




持续集成之“Everything is code”
在前文《软件自我识别》中,我们讨论了如果使软件做到自我识别,以促进自动化部署和版本检测等工作。 随着互联网的飞速发展,以及基础设施的改进,越来越多的业务被放在了“云”端。管理数千台服务器和各种应用程序的不同版本已经是一种常规事务了。那么如果管理好这些机器和代码吗?本文将介绍一些最佳实践,来帮助大家更好的完成相关的事务。
一、测试代码不是二等公民
业务压力让团队人力显得有点儿紧张。一天下午,大家在紧张的工作着,新的版本即将发布了。突然,有两个同事的对话引起了 Joe 的注意。
“Hi,Sam。过来看一下,我这里有个自动化测试失败了。”刚刚加入团队的测试人员 Jared 叫了 Sam 一声。
“咦?我本地没有这个测试,可我更新过我本地的代码了呀?”Sam 一脸茫然地应到。
“哦,是吗?不会吧。我也是刚刚从 SVN 上更新了代码。”Jared 说道。
“Jared,你再更新一下,也许是你在我提交之前更新的呢。。。哦,还是一样的结果。那到我的工作站上看一下吧。”
“噢,原来你把测试放在了这里。”Sam 恍然大悟的样子,“我们两个人使用的测试套件版本是不一样的。根据用户的反馈,我们重新修改了产品的一个小功能,所以,这部分功能的原有自动化验收测试逻辑就不对了。”。SVN 代码仓库的目录结构如图 1 所示。
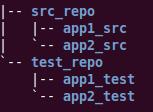
图 1 产品代码与测试代码分离
这时,Joe 也凑了过来。“嗯。我们应该修改一下我们的代码在 SVN 中的组织结构。把测试代码和产品代码放在同一个代码库中,做到产品代码与测试代码同源。”
Jared 问道:“为什么要这么做呢?我在上一家公司的时候,测试团队也是把功能测试用例放在公司自行开发的一个测试用例管理平台上进行管理。当需要做老版本的回归测试(比如 V1.0)时,我们只要在这个平台上勾选上该版本对应的测试用例,再点击‘执行’按钮,就可以了。当有新版本, 比如 V1.1 时,只要把 V1.0 的所有测试用例复制一份,标记为 V1.1,并在其上修改就可以了。测试代码的组织方式常常是使用目录结构来分离版本。”如图 2 所示。

图 2 以目录方式对测试用例进行管理
Joe 回答到:“你刚才所说的做法,我也在其它公司见过。这种做法常见于使用传统瀑布开发模式的团队,即开发阶段与测试阶段分离。在开发阶段,大家并不会频繁运行相应的自动化测试,这些自动化测试是为测试人员服务。而在我们这里,自动化测试是为所有人服务的,开发人员随时都会运行测试。其实,我们大部分的测试都已经与产品代码放在了同一个代码仓库中了。只是这一部分是比较老的代码,需求也一直没有变化,自动化测试也一直运行成功,所以就没什么动力去迁移这部分测试代码。”
Joe 停顿了一下,喝了一口咖啡,接着说道:“当我们做到产品代码和测试代码同源时,我们只需要从一个 svn 代码仓库中签出某个版本的源文件,就同时得到到产品代码,以及与该版本相对应的测试代码。所以,不会出现版本不一致,或者需要手工挑选测试用例的问题。现在服务器很多,应用程序使用灰度放量发布的方式,在生产环境中可能会有多个版本。假如正在运行的某个版本出现了问题,需要修复,那么,我们很容易就能拿到与其对应的所有代码。因此,不能把测试代码作为代码中的二等公民,而是应该得到与产品代码同样的重视。我们代码库中的目录结构是这样的。”如图 3 所示。
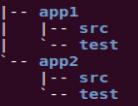
图 3 测试代码与产品代码同源
二、配置信息也是代码
Alex 此时也凑了过来,接道:“不只是对代码需要一视同仁,配置信息也一样要放到代码仓库中。这方面,我们也是有着痛苦经历的。记得是几个月前,那时候我们的产品还不大,为了快速调整,我们经常在生产环境中直接修改配置信息,如数据库连接,功能开关项或者 IP 地址什么的。结果,每次准备上线前的测试时,都要到生产环境上去下载一份配置信息。有一次,生产环境上的一台机器出了问题,结果那台机器上的所有信息都丢了,害得我们到处找,花了很长时间才把那台机器重新配置好。现在都放在代码仓库中,就可靠多了。”
“配置信息是指哪些呢?”Jared 问道。
Joe 回答道:“配置信息包括应用程序相关的配置,以及程序部署时的相关配置。应用程序相关的配置是指影响应用程序行为的配置项,比如某个功能的开关、数据库连接、缓存的大小等等。程序部署时的相关配置是指部署在不同机器上的程序组件是如何相互连接的,如 IP 地址等等。”
“那有些配置信息是动态生成的,那怎么把它放到 SVN 中呢?”Jared 接着问道。
“我们首先要把动态信息与静态信息分开。一般对于动态信息来说,只要把其变动的规则保存在 SVN 中就可以了。” Alex 答道。“比如,某些 IP 地址或内部域名是自动配置的,那么就把自动配置的脚本放到 SVN 中就行了。这样,一旦出了问题,我们也可以确切地知道,所用的分配规则是什么样的。”
“那生产环境的配置与测试环境的配置不同,与开发环境的配置也不同,怎么办呢?”Jared 穷追不舍。
“这个好办,只要存三份配置,对应三种不同的环境就可以了。”Joe 笑道,“所以,我们代码目录结构是这样的。”他拿起笔,在纸上画了一下,如图 4 所示。

图 4 以业务为核心组织产品结构
三、脚本文件也是源代码
原文转自:http://kb.cnblogs.com/page/127846/
