




单元测试中测试用例的设计方法
1. 用于语句覆盖的基路径法
基路径法保证设计出的测试用例,使程序的每一个可执行语句至少执行一次,即实现语句覆盖。基路径法是理论与应用脱节的典型,基本上没有应用价值,读者稍作了解即可,不必理解和掌握。
基路径法步骤如下:
1)画出程序的控制流图
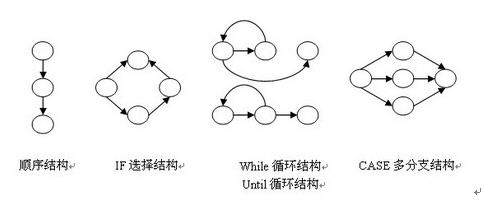
控制流图是描述程序控制流的一种图示方法,主要由结点和边构成,边代表控制流的方向,节点代表控制流的汇聚处,边和结点圈定的空间叫做区域,下面是控制流图的基本元素:
以下代码:
|
void Sort(int iRecordNum, int iType) { int x = 0; int y = 0; while(iRecordNum-- > 0) { if(0 == iType) { x = y+2; break; } elseif(1 == iType) { x = y+10; } else { x = y+ 20; } } } |
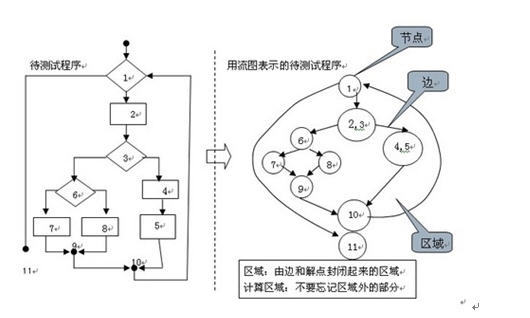
可以画出以下控制流图:
2)计算程序环路复杂度
环路复杂度V(G)可用以下3种方法求得:
(1) 环路复杂度等于控制流图中的区域数;
上图中,有4个区域,V(G) = 4。
(2) 设E为控制流图的边数,N为结点数,则环路复杂度为E-N+2;
上图中,V(G) = 10(边) – 8(结点) + 2 = 4。
(3) 设P为控制流图中的判定结点数,环路复杂度为P+1。
上图中:V(G) = 3(判定结点) + 1 = 4。
环路复杂度是独立路径数的上界,也就是需要的测试用例数的上界。
3)导出基本路径集
基本路径数等于V(G)。根据上面的计算方法,可得出需要的基本路径数为4。路径就是从程序的入口到出口的可能路线,基本路径要求每条路径至少包含一条新的边,直到所有的边都被包含。需要提醒的是:基路径法和路径覆盖是两回事,用于设计用例的基路径数一般小于全部路径数,即基本路径集不是惟一的。基路径法完成的是语句覆盖,而不是路径覆盖。下面选择四条基本路径:
路径1:1-11
路径2:1-2-3-4-5-1-11
路径3:1-2-3-6-8-9-10-1-11
路径4:1-2-3-6-7-9-10-1-11
4) 设计用例
根据上面的路径,可以设计出以下用例:
路径1:1-11
用例1:iRecordNum = 0
路径2:1-2-3-4-5-1-11
用例2:iRecordNum=1, iType = 0
路径3:1-2-3-6-8-9-10-1-11
用例3:iRecordNum=1, iType = 1
路径4:1-2-3-6-7-9-10-1-11
用例4:iRecordNum=1, iType = 2
从上述步骤可以看出,基路径法工作量巨大,如果用于五十行左右的函数,将耗费大量的时间,而五十行代码的函数实在是太普通了。这种成本巨高的方法,其测试效果如何呢?测试效果完全与成本不匹配,首先,基路径法完成的只是代码覆盖,这是最低级别的覆盖,其次,整个设计过程都是依据已经存在的代码来进行的,没有考虑程序的设计功能,是典型的“跟着代码走”,不足是显而易见的。综上所述,基路径法没有实际应用价值。
2. 用于MC/DC的真值表法
设计用于MC/DC的用例,可以先将条件值的所有可能组合列出表格,然后从中选择用例,称为真值表法。例如判定A || (B && C),条件组合如下表:
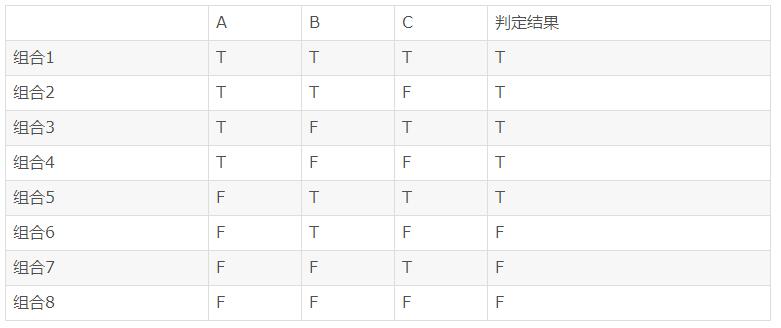
为了使A独立影响判定结果,选择B和C相同,判定结果相反,且A相反的组合:组合2和6;
为了使B独立影响判定结果,选择A和C相同,判定结果相反,且B相反的组合:组合5和7;
为了使C独立影响判定结果,选择A和B相同,判定结果相反,且C相反的组合:组合5和6。
因此,组合2、5、6、7符合MC/DC要求。符合MC/DC要求的用例集不是惟一的。
为了提高效率,可以使用工具来生成真值表和找出符合要求的组合,有些商业工具具有这种功能。自行开发难度也不大,下面提出开发MC/DC用例设计小工具的思路,有兴趣的读者可以尝试一下:
1)用一个简单的词法和语法分析器解析判定表达式,计算条件数量;
2)生成真值表;
3)用一个逻辑表达式计算器,针对每个条件C,扫描真值表,找出符合以下要求的组合:除条件C外,其他条件取值相同;将条件C的真值和假值分别代入判定表达式,判定的计算结果相反。
4)针对找出的组合,设计两个用例,条件C分别取真和假。
需要注意的是,判定中可能存在完全相同的条件,例如:
(A==0 || B == 1) && C == 2 || (A==0 && D == 3)
针对A==0设计MC/DC用例时,前一个A==0取反,后一个A==0也会跟着取反,如果后一个A==0视为其他条件,则不能实现MC/DC覆盖,因此,计算判定值时,两个A==0应视为同一个条件。
3 边界值法
边界值法假定错误最有可能出现在区间之间的边界,一般对边界值本身,及边界值的两边都需设计测试用例。
如下函数:
|
//参数age表示年龄 int func(int age) { int ret = 0; //… do something return ret; } |
参数age表示一个人的年龄,假设有效的取值范围是0-200,那么,用边界值法可以得出以下用例(省略输出):
用例1:age = -1;
用例2:age = 0;
用例3:age = 1;
用例4:age = 199;
用例5:age = 200;
用例6:age = 201;
通常,程序对输入还会分段处理,例如,年龄在10以下,为儿童,需要特别照顾;年龄在60岁以上,为退休老人,不能安排工作,那么,10和60是内部边界,也要设计测试用例:
用例7:age =9;
用例8:age = 10;
用例9:age = 11;
用例10:age = 59;
用例11:age = 60;
用例12:age = 61;
边界值法需要了解数据所代表的实际意义,此外对于枚举类型等非标量数据不适用。边界值法对于复杂的软件项目来说,适用范围有限。
4 等价类法
先从代码编写的思路说起。程序员编写一个函数的代码,会如何做呢?
首先,了解代码功能。程序的功能是什么?无非就是:有哪些输入?执行什么操作或计算?产生什么输出?
然后,将功能细化,形成一个或多个功能点。一个功能点就是一类输入及其处理。什么叫“一类”输入?程序可能有无数输入,但代码并不需要用无数个判定来对每个输入分别做处理,只需将输入分类,需要做相同处理的输入归于一类,这就是“等价类”。从编程角度来说,“等价类”是指计算或操作过程的“等价”,一个等价类就是处理过程完全相同的输入的集合。程序中通常用判定来识别分类,一个判定就是一次分类,嵌套的判定则会造成分类数量的翻番。
所以,函数代码编写的核心思维就是等价类划分和处理。一个函数要完全正确,关键是等价类的划分要正确完整,且每个等价类的处理正确。
举个例子,现在要编写一个函数,将字符串左边的空格删除。函数原形如下:
| char* strtrml(char *str); |
功能:
将str左边空格删除,并返回str本身。
功能点:
1. 左边有空格:删除;(正常输入)
2. 左边无空格:不作处理;(正常输入)
3. 全部是空格:全部删除;(正常输入)
4. 空串:不作处理;(边界输入)
5. 空指针:直接返回。(非法输入)
不一定需要针对每个功能点分别写代码,因为程序中的if、for、while等语句本身具有“如果不符合条件就跳过”的含义,所以很多功能点是可以共用代码的,例如,前4个功能点只需要相同的代码,不过,编程时对功能点的考虑还是要全面。
既然函数没有错误的关键是等价类划分正确完整且处理正确,那么测试时,只要把输入的等价类都列出来,并设定正确的预期输出,进行测试就行了。
这就是通常说的“等价类”法,从测试角度来说的“等价”,是指测试效果上的等价,即同类中一个数据测试通过,可以肯定其他数据也会测试通过。
用例设计的首要工作是设定输入。输入有哪些呢?要从正常输入、边界输入、非法输入三方面考虑,每方面进一步划分形成等价类,即要考虑:有哪些正常输入?有哪些边界输入?有哪些非法输入?
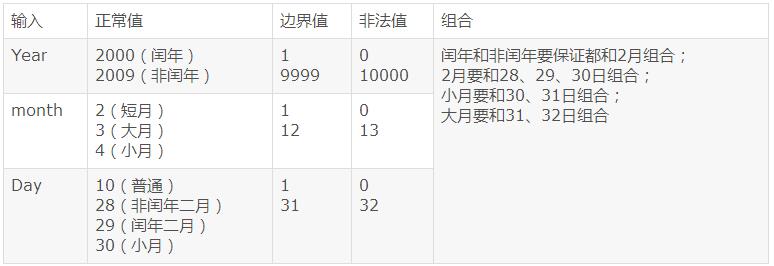
多个输入时,例如有多个参数,首先把各个参数的等价类列出来,然后要考虑参数之间是否存在特殊的组合关系。例如下面的函数:
|
//计算某年某月某日是星期几,参数分别表示年月日 int Date(int year, int month, int day); |
用例如下表(假设year的有效范围是1-9999):
用例的输出是比较容易被轻视的工作,但是,没有充分且正确的预期输出,用例基本上没有意义,就像医生要求病人做一大堆检查,却不看检查结果一样。预期输出要根据程序的设计功能确定正确的值。一个用例的预期输出可能有多个。
等价类法是与程序的基本特性“对数据分类处理”相匹配的方法。对于一个函数来说,如果对数据的分类正确且完整,每一个分类处理正确,那么,程序就没有问题。同样,测试时,只要依据设计功能,找出所有等价类,那么,用例就是完整的。所以,用例的完整性,本质上是指等价类是否划分正确且完整,每一类的正确输出是否均依据设计功能正确设定。
使用了等价类法后,是否需要使用其他方法呢?
等价类法从“有哪些正常输入?有哪些边界输入?有哪些非法输入?”三个方面来考虑等价类,因此,边界值法是等价类法的一部分。
常见的用例设计方法中还有正交法和错误推测法。正交法考虑数据的组合,实际上,如果程序对输入数据的组合需要判断处理,也是一种等价类划分,但正交法会产生大量的多余组合,且可能缺少必要的组合,因此不推荐采用正交法,应该根据数据的实际意义自行组合。单独从错误推测角度去设计用例未免太不可靠,但错误推测法可以作为检查等价类是否完整的一种思路,即用等价类法设计用例后,可以考虑哪些输入比较容易产生错误,以检查是否遗漏,这只是一种检查思路,也包含在等价类法之中。总之,用例设计只需使用等价类法,但可以从多种角度检查等价类的完整性。
原文转自:www.uml.org.cn/Test/201811193.asp
