




用 Apache Derby 进行开发 —— 取得节节胜利: 用 Apache Derby 进行数据库开发,第 2 部分
关系数据库系统基础
在开发数据库应用程序之前,需要理解它的基本概念。这一节介绍在 Apache Derby 中可以使用的数据类型,以及对设计和创建有用的 Derby 数据库应用程序的能力有影响的规则。
关系数据库容纳数据。数据可以是不同类型的,例如数值型、字符型或日期型。在数据库中,数据被组织到叫做表 的逻辑单元中。表就像工作簿一样,因为它包含数据行。每行由许多列组成。列容纳特定数据类型的数据,例如整型值或字符串。在多数情况下,一个数据库有多个表。为了将表关联在一起,数据库设计师利用表之间的自然(或人为)链接。在工作簿中,可以通过单元格的值链接不同工作簿中的行。同样的概念在关系数据库中也存在,用来进行链接的列叫做键列(key column)。
为了让表或列的用途更容易理解,应当选择合适的名称。对于不同的数据库,命名约定可能不同。对于 Apache Derby 数据库系统,名称应当:
- 不区分大小。
- 最长 128 个字符。
- 必须以字母开头。
- 必须只包含 Unicode 字母、下划线和 Unicode 数字。
通过把名称放在双引号中,可以避开 这些规则,使用双引号允许名称区分大小写以及包含附加字符(包括空格)。但是,这么做通常是不好的做法:它要求名称总被括在双引号中,很容易把维护代码的其他人弄糊涂。
|
关联的表通常组织在一起,形成一个模式(schema)。可以把模式当成特定数据库中所有相关结构定义的容器。在指定模式中,表的名称必须惟一。所以,通过使用模式,可以在不同模式的范围内拥有名称相同的对象(例如表)。在使用 Apache Derby 数据库时,表总在模式中。如果没有显式地指定模式,Derby 就会隐式地使用内置的 apps 模式。叫做 sys 的第二个内置模式用来隔离系统表。
可以用模式名对名称进行限定(qualify)。要做这件事,可以在模式名后加圆点,然后加表名。例如,bigdog.products 表示 bigdog 模式中的 products 表。没有相应的模式名,表名就被认为是未限定的(unqualified),例如 products。当模式名和表名都完全指定的时候,就像 bigdog.products,名称被称为完全限定的(fully qualified)。
从抽象意义上来说,这些数据库概念看起来可能让人混淆。但在实践上,它们相当简单。例如,假设有一个商店,叫做 Bigdog's Surf Shop,这家店销售各种商品,例如太阳镜、衬衫等等。如果想赢利,就必须管理库存,以便可以容易地订购额外的商品或改变供应商,从而把开支控制在最小。跟踪这些信息的一个简单方法,就是用表格式编写条目,如 图 1 所示。
图 1. Bigdog's Surf Shop 的示例模式
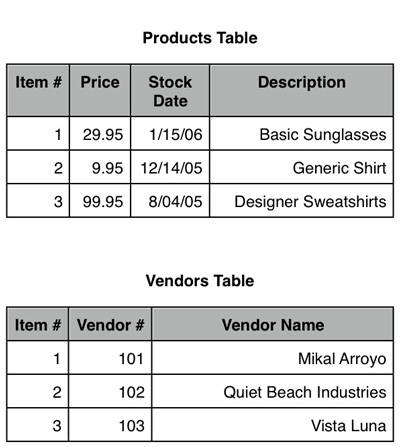
从这个简单的可视设计中,可以容易地把业务逻辑直接映射到数据库表。有两个表:Products 和 Vendors,它们自然地通过商品名称链接在一起。列的数据类型很容易确定。这篇文章其余的部分将侧重于在 Derby 数据库中创建 Bigdog's Surf Shop 的示例模式 —— 模式中包含这两个表。
|
处理关系数据库:结构化查询语言
|
数据库系统会成为软件中复杂的部分,特别是在规模扩大到支持企业级应用程序的时候。所以,可以想像每个数据库都会有自己的应用程序编程接口(API),而这些 API 可能彼此不同。当关系数据库刚开发出来的时候,情况就是这样。但是,幸运的是,许多开发商同意开发一个标准的语言,用来访问和操纵数据库。这个语言称作结构化查询语言(或 SQL,发音是 sea-quill)。至今已经形成了多个官方标准版本,包括 1992 年的版本,这一版被称为 SQL-92,还有 1999 年的版本被称为 SQL-99。Apache Derby 数据库为 SQL-92 标准提供了几乎完整的实现,所以用 Deryby 开发的应用程序可以容易地移植到其他数据库系统。
SQL 有两个主要部分:数据定义语言(DDL)和数据操纵语言(DML)。DDL 命令用来创建、修改或删除数据库中的项目(例如表)。DML 命令用来在数据库表中添加、修改、删除或选择数据。这篇文章后面的部分将提供对 SQL 的 DDL 部分的基本介绍。未来的文章将侧重于 DML 命令和更高级的 DDL 命令。
SQL 数据类型
SQL 作为一个编程语言,定义了丰富的数据类型层次结构。数据库已经变得更强大了,所以这个类型层次结构也变得更复杂。但是最简单的数据库并不要求使用所有允许的类型,通常只需要保存数值型、字符型和日期(或时间)数据。为了简单,表 1、2、3、4 显示了 Derby 中实现的基本 SQL 数据类型。
如表 1 所示,Derby 提供了对三种整型数据类型的支持。这些类型由它们可以保存的整数的范围区分,也就是由它们在数据库中需要的存储空间区分。在设计数据库时要记住的一个关键问题就是,应当一直把表使用的空间控制在最小。一般来说,表越小,性能越高。但是必须能够在生成的表中保存需要的数据。231 等于 2,147,483,648,263 等于 9,223,372,036,854,775,808,所以使用这些类型可以保存非常大的整数!
| 数据类型 | 最小值 | 最大值 | 示例 | 说明 |
|---|---|---|---|---|
SMALLINT |
-32768 (-215) | 32767 (215 - 1) | itemNumber SMALLINT |
2 字节整数表示 |
INT |
-231 | 231 - 1 | itemNumber INT |
4 字节整数表示 |
BIGINT |
-263 | 263 - 1 | itemNumber BIGINT |
8 字节整数表示 |
多数数值型数据不能用整数表示。Derby 对实数提供了多种格式的支持:单精度浮点、双精度浮点以及准确的算术表示,如表 2 所示。
| 数据类型 | 最小值 | 最大值 | 示例 | 说明 |
|---|---|---|---|---|
REAL |
-3.402x10+38 | 3.402x10+38 | price REAL |
IEEE 浮点数(4 字节) |
DOUBLE |
-1.79769x10+308 | 1.79769x10+308 | price DOUBLE |
IEEE 浮点数(8 字节) |
DECIMAL |
31 (最大精度) | price DECIMAL(5,2) |
准确算术表示 | |
如果从未遇到过准确精度数据类型,那么对算术类型和浮点类型可能有些迷惑。区别在于一个事实:计算机中使用的浮点数据类型无法包含每个实数。这看起来可能有些怪,但是想想实数的数量是无限的。大多数实数都无法保存在几个字节的内存中。对于某些应用程序,精度的损失是可以接受的,而在许多情况下,则不可接受。例如,财务应用程序不能容忍仅仅因为某个数字不能保存在计算机中,就损失金钱。
这个问题的解决方案是使用 DECIMAL 数据类型,它可以控制计算机存储的数字位数(精度)和小数点后的位数(刻度)。要创建算术类型,应当指定保存的数据的精度,并可选地指定数据的刻度。DECIMAL 数据类型需要的存储空间通常要比浮点数据类型大得多。所以应当小心地使用这个类型,否则应用程序的性能会降低。默认情况下,DECIMAL 类型的刻度为 0,这意味着 DECIMAL 数据类型模拟了整数类型。
数值类型有多个同义词。例如,DECIMAL 数据类型可以缩短为 DEC 或表示为 NUMERIC。DOUBLE 类型也可以表示为 DOUBLE PRECISION,虽然为什么在需要双精度数字时要输入额外的单词,原因不明。更常用的同义词是 FLOAT 类型,它拥有任意的浮点精度,可以在声明数据类型时指定,例如 FLOAT(val)。精度必须是小于 53 的正整数;如果不是,就会出错。如果指定了小于等于 23 的精度值,FLOAT(val) 就等价于 REAL;如果精度在 24 和 53 之间,那么 FLOAT(val) 等价于 DOUBLE。
除了数值类型,数据库中最常用的保存数据的另一个类型是字符数据。字符数据的示例包括产品说明、人名或地址信息。Derby 提供了保存字符数据的两个简单技术:CHAR 类型和 VARCHAR 类型,详情如表 3 所示。对于这两种类型,都可以指定 length 参数,如果没指定,默认为 1。在这两个字符数据类型之间有两个主要区别。首先,CHAR 类型的最大长度是 254 个字符,而 VARCHAR 类型最多可以容纳 32,672 个字符。第二个区别比较微妙:CHAR 类型的长度总是指定的长度。如果没有指定足够的字符,那么会插入额外的空白来填满剩余位置。而使用 VARCHAR 时,字符的数量是可变的,不执行额外的填充。
| 数据类型 | 最大长度 | 示例 | 说明 |
|---|---|---|---|
CHAR |
254 | description CHAR(128) |
定长字符串 |
VARCHAR |
32,672 | description VARCHAR(128) |
变长字符串 |
因为长度可变,所以 VARCHAR 类型在实际的存储空间方面会更有效率,但在性能上效率就会更低。CHAR 数据类型有助于性能提高,因为数据库确切地知道每个 CHAR 列有多大,所以在读写数据时就可以执行某种性能优化。VARCHAR 列的最大长度看起来可能足够大了,但是 Derby 还提供了更大的字符数据类型,这个类型将在未来的文章中讨论。
Derby 提供了最后一类简单的数据类型来保存日期和时间,如表 4 所示。TIME 数据类型以 24 小时格式保存小时、分钟和秒(HH:MM:SS)。DATE 数据类型保存月、日和年,可以用不同的格式指定,包括以下格式:
yyyy-mm-ddmm/dd/yyyydd.mm.yyyy
| 数据类型 | 最小值 | 最大值 | 示例 | 说明 |
|---|---|---|---|---|
TIME |
00:00:00 | 24:00:00 | start TIME |
时间表示(精确到秒) |
DATE |
0001-01-01 | 9999-12-31 | stockDate DATE |
日期表示(精确到天) |
Derby 还提供了 TIMESTAMP 数据类型,把 TIME 和 DATE 数据类型组合到一个类型中,表示准确的时间。
|
在 Derby 中创建表
目前为止,已经学习了如何设计表,包括规划表的列和定义每个列的数据类型。在正确地设计了表之后,用 SQL 创建表的方法就很简单了。清单 1 显示了在 Derby 中创建表的正式语法。
清单 1. Apache Derby 的 CREATE TABLE 语法
|
第一次看这个语法时,可能感觉到迷惑不解。但是有了基础之后,接下来就容易了;而且如果想掌握 Derby,对正式语法的理解是必需的。方括号([ 和 ])中的是可选参数。从正式语法中可以看出,模式名是可选的,在必需的头一个列之后(创建连一个列都没有的表是没有意义的),其他列定义或表级约束都是可选的。
您可能理解列定义的含义,但是可能不理解约束 的意义。约束有两种类型:表级约束和列约束。约束通过某种方式对列或表进行限制。例如,可以用约束要求列总要有实际的值(没有 NULL 值),或者列中的每个项必须是惟一的,或者列被自动分配默认值。在未来的文章中将更详细地介绍约束。
最后一个结束方括号之后的星号(*)代表可以包含一个或多个包含项。这意味着表必须有一个或多个列级或表级约束。竖线(|)表明 “可有可无” 条件。在这个语法示例中,必须定义一个新列或者定义一个表级约束。花括号({ 和 })把相关项组织在一起,而圆括号(( 和 ))中是必需的元素 。最后,分号(;)表示 SQL 语句的结束。
把这些规则投入使用则相当简单。清单 2 显示了如何用 Derby 提供的 ij 创建前面在 图 1 中演示的表。
清单 2. 在 Apache Derby 中创建表
|
与 Derby 数据库进行交互的最简单方式是使用 ij 工具,在这个系列的第一篇文章 “用 Apache Derby 进行开发 —— 取得节节胜利:Apache Derby 介绍”(developerWorks,2006 年 2 月)中已经介绍过。如果按照 清单 2 中的步骤进行,就会创建一个新的数据库,名为 test。如果 test 数据库已经存在,在发出 connect 语句时,会得到警告消息。可以安全地忽略这个警告。接下来,隐式地创建一个名为 bigdog 的新模式,并显式地创建两个新表 —— products 和 vendors —— 这两个表保存在 bigdog 模式中。模式的创建所以是隐式的,是因为没有发出 CREATE SCHEMA 语句。
products 表有四个列:itemNumber、price、stockDate 和 description。itemNumber 列提供了每个商品(或列)的惟一标识,它上面还有列级约束,强制要求提供正确的值(NOT NULL)。如果没有这个要求,itemNumber 列就无法保持惟一,因为多个行都可能被分配 NULL 值。price 列创建为 DECIMAL 数据类型,精度为 5,刻度为 2。这意味着每个商品的最高价格可以是 $999.99。最后两个列很简单:stockDate 列以 Date 类型保存,description 列以字符串类型保存,最长 128 个字符,使用的空间是实际的字符串长度。
vendors 表有三列:itemNumber、 vendorNumber 和 vendorName。在这个示例中,itemNumber 和 vendorNumber 列都有列级约束(NOT NULL)。另外,vendorName 列以字符串类型保存,最大长度为 64。因为 vendorName 列用 CHAR 数据类型保存,所以总是保留 64 个字符空间。
在创建了各种项目之后,可能想知道是否有种简单的方式可以查看数据库中保存了什么项目。幸运的是,答案是肯定的,可以使用 dblook 工具。运行这个工具,如 清单 3 所示,提供了特定数据库中已经创建的项目的详细清单。
清单 3. 用 dblook 查看模式
|
dblook 工具是一个 Java 类,可以用它方便地把数据库的内容输出到控制台。在命令行上运行它,就像运行其他 Java 程序一样;惟一增加的就是使用 -d jdbc:derby:test 参数,这个参数指定 dblook 工具应当查询的数据库。如果能运行 ij 工具,那么 dblook 类文件就已经存在于 CLASSPATH 中了。如果不是这样,请参考这个系列中的 第一篇文章,获得正确设置 CLASSPATH 的详细说明。正如 dblook 工具的输出所示,test 数据库包含 bigdog 模式,这个模式包含 products 和 vendors 表。另外,对这两个表的列也有详细描述。
|
删除 Derby 中的表
没有什么事情是完美的。当错误地创建了表或者表不再需要的时候,该怎么办?简单的答案是从数据库中删除表。而且,如果必要,再创建一个替代表。删除表很容易,当然这意味着,在做这件事的时候应当非常小心 —— 不会弹出对话框要求您确认是否真的想删除!
从数据库中删除(或者更正式地说,撤下(drop))一个表的完整语法是:
DROP TABLE [schemaName.]tableName ;语法很简单:把完全限定名称和分号放在 DROP TABLE SQL 命令后面,就完成了。清单 4 中在新创建的临时表上演示了删除表的过程。
清单 4. 从 Derby 数据库删除表
|
|
结束语
现在您已经走上了操作 Apache Derby 数据库的道路。目前您已经掌握了基本的数据库概念,包括模式、表和列,还看到了使用名为 Bigdog's Surf Shop 的虚拟公司对这些概念的演示。要操作像 Derby 这样的数据库,需要学习 SQL,它是与数据库进行交互的标准语言。这篇文章还介绍了可以用来在 Derby 数据库中保存数据的基本数据类型。把这些概念融合在一起,您学习了如何用 Derby 创建和删除表,还使用 Derby 的 dblook 工具输出了数据库的模式内容。
