




使用 GTK+ 进行健壮的国际化
了解如何使用 GTK+ 库创建支持多种语言并适用于世界不同的地方的图形用户界面 (GUI) 应用程序。本文向您介绍如何避免常见的错误和创建可以可靠地处理国际需求的应用程序。
世界正在不断地发展。如今,您不能够忽视全球市场的存在,并且计算机也不是那些花费大量时间和精力去研究其中复杂情况的少数人的昂贵的玩具。因此,创建适合于国际用户的即时可用的应用程序的需求也在日益地增长。
通常,图形用户界面 (GUI),特别是 GTK+ 应用程序也不例外。实际上,经过巨大改进的国际化(以下称为 i18n,表示单词 internationalization i 和 n 之间的 18 个字母)支持是从 GTK+ V1.x 到 V2.x 的重大更新中的一个非常重要的部分。
本文说明了如何使用这些功能来创建可以理解和尊重不同文化和语言的用户的需求的 GUI。您将了解可以创建哪些应用程序,并预览如何实现它们,同时本文还提供了一些使得您能够踏上正确的开发之路的建议。
国际化需求
|
很明显,GTK+ 的创建者从一开始就意识到了国际化的需求,并且将其深深地嵌入到 GTK+ 库中的各个方面。为了达到这个目标,其中存在许多的功能,您可以使用它们来创建在面临多种语言用户需求时正常运行的应用程序。
这些功能中包括:
- 在整个库内部使用了 Unicode:通过使用 Unicode,可以创建真正的多语言 应用程序,而不仅仅是用多种语言编写的应用程序。例如,以阿拉伯语运行一个应用程序,并向日本学者显示俄语注释,使用 Unicode 则完全可以实现。要实现这种情况,所有传递给 GTK+ 例程和来自 GTK+ 例程的字符串都应该使用 UTF-8 编码方式,除非显式地声明使用其他的编码方式。(有关 UTF-8 更多的内容,请参见侧栏。)
- 使用 Pango 库进行所有文本的表示:Pango 设计用于将 Unicode 文本块转换为适当的屏幕表示形式,并处理一些细节问题,如字体选择和替换、文本度量、可视化字形表示、组合和聚集、类似连字之类的可视形式的替换和其他高级排印特性,以及 Unicode Bidi(双向文本)算法的实现。(Bidi 允许您正确地表示从右到左 (RTL) 的文本和混合语言,如阿拉伯语。)Pango 有效地替换了旧的文本表示方式,并且应该在所有的表示需求中使用它。
- 通过 GNU gettext 库实现对用户可见消息的使用和本地化 (l10n) 的缺省支持:通过使用 gettext 库,GTK+ 可以适合用户运行所处的任何区域,并以该用户的语言显示 GUI(如何合适,可以使用相应的数据文件)。GTK+ 还包括了(通过 GLib)对在自定义应用程序中使用 gettext 的缺省支持,不过您可以随意使用其他的可选解决方案。
- 不固定的定位:尽管和国际化没有什么直接关系,但是仍然非常重要的是,GTK+ 没有使用固定的定位,这是以多种可能的语言正确地显示用户界面 (UI) 的先决条件。如果您曾经看到过一个应用程序的本地化版本,它所显示的消息在原始英语文本结束处进行了截断,那是因为程序员进行了这样的布局,而 GUI 库无法对其进行调整,但您可以放心,这在 GTK+ 中是决不会发生的。它总是根据需要分配空间,而不是事先在开发过程中进行指定。
|
为国际化准备您的应用程序
正确的国际化需要两个互补的资产。首先是正确的设计思想,摒除特定于任何语言的假定,并且能够意识到当您的应用程序迁移到另一种语言时可能或将会发生的变化。其次是正确的工具集,一种能够支持摒除假定 编程风格的工具集。
下面,您将看到关于可能遇到的问题和可以应用的解决方案的简要概述。这个概述并不是全面的或权威性的:正确的国际化是一个广泛而深入的主题。但是对于本文中没有进行深入介绍的所有细节内容,我都提供了相应的参考资料的链接,以便为您提供所需的资源。
请确保您需要进行本地化
根据过去的经验所知的一些对国际化的错误处理,如为不同的语言配送不同的、不兼容二进制代码或使用 16 进制的编辑器胡乱切割数据文件,这些都不是正确的解决方案,并且在这里我也不会对它们进行讨论。唯一真正的处理国际化的方法是正确地标记和提取那些需要进行本地化的内容,并从此处开始将这些部分作为单独的实体进行独立的处理。您将在“代码”部分中了解如何进行这样的处理。
了解语言之间的差异
显现出这些差异的一种情况是在自动生成的消息中,特别是那些涉及到复数的消息。请考虑下面的两种方法:
|
和
|
这两种方法都是错误的,而且在英语(即使在英语中也是有问题的,比如您需要处理 fish 或 stories,而不是 files)以外的语言中没有任何价值,它们不适合于实际应用,除非您的目的是创建笨重和糟糕的界面。另外,第一种解决方案 存在严重的可读性问题。
相反,可以使用一种专门的解决方案,如 GNU gettext 库中的 ngettext() 函数:
|
使用提供的数值参数和语言翻译器提供的规则,ngettext() 函数可以在运行时为指定的语言确定正确的格式,或者在不存在任何格式时使用后退字符串(上面的代码中两次使用了该字符串)。有关使用 ngettext() 函数的详细信息,请参考 gettext 库手册(请参见参考资料部分)。
从上面的示例中可以看到,无论是否涉及到复数,您都不应该试图通过字符串连接或其他的代码技巧来生成消息。这样做可以防止您的翻译器根据它们的需要而更改句子的顺序,并将这些要翻译的内容变成难以理解的、支离破碎的文本(因为它们将得到一些文本块而不是一个完整的句子,并且没有任何关于这些文本块之间的关系的提示信息)。请始终使用完整的、有意义的句子,并将关联的文本组织在一起。
遵守文化习俗
国际化决不仅仅只是翻译字符串。不同语言之间的差别在于它们所使用的小数点分隔符(逗号还是点号)、日期格式、使用 12 小时还是 24 小时的时钟、货币格式等等。另外,您还需要处理字母的排序和一般文本操作等常用的操作,即什么是字母、每个字母在字母顺序中的位置、什么是标点符号等等。所有这些细节信息都位于所谓的区域设置 定义文件中,并且假定来自于操作系统。GLib 对不同操作系统之间的差异进行了抽象,并且提供了一些关于文本和区域的实用函数。请花些时间浏览 GLib API 参考手册中关于 Unicode、日期和时间、字符串的部分(请参见参考资料部分)。
操作系统和 C 语言提供的可以识别区域设置的服务也有另一方面的问题。请注意,在缺省情况下,大多数 C 库函数都以一种与区域相关的方式运行。这就意味着,例如,如果您在一台美国的计算机上使用 strtod() 函数保存了一个浮点数值,并稍后试图在一台波兰的计算机上读取该数值,那么这个操作将会失败,因为这两种区域设置使用了不同的小数点分隔符。相反,在您需要保存数据时,如配置文件,可以使用 GLib 提供的 g_ascii_* 系列函数。
请多加小心
国际性问题要比您可能预期的更加复杂。例如,在您对图形进行选择时,请加以小心,因为对您来说可能是一个简单的图标,而对不同文化的人来说则可能是一个严重的冒犯。这条规则特别适用于合并人体不同部分的图标。请始终使用系统提供的常用资源,如图标。如果没有合适的常用图像,那么需要对您所使用的图像进行注册,以便本地供应商可以使用主题来替换它,而不必对源代码进行修补。
重用原则也适用于代码:不要重写库中已经提供的任何与区域设置有关的函数。如果您发现库中缺少某个函数,请参见 GTK+ 开发人员邮件列表(请参见参考资料部分):它可能是一个错误,并且在您提交修补程序时,您的代码将使所有人获益。
请非常 小心地处理任何内容,即使仅具有微不足道的政治意义:在您引用旗帜、地图或具有政治含义的名称之前,请三思。排序代码中的错误可能令人讨厌,但是不得不从整个次大陆召回您的产品,就像 Microsoft® 对 Microsoft Windows® 95 操作系统所做的那样,这比令人讨厌要糟糕的多。
请始终使用 Pango 进行文本的表示
您无法再创造出处理世界上每种语言的代码,所以不应该考虑使用块来构建文本,因为文本并不是块。别再犹豫了:请使用 Pango。
|
代码
既然您已经了解了国际化的基本思想,那么接下来看看如何在 GTK+ 代码中处理它们。
首先,您必须声明一些允许 gettext 库为您的应用程序找到正确消息的名称。请注意,在现实的场景中,构建系统将为您处理这些名称,但是出于我们的需要,可以使用下面的名称:
|
在此之后,您必须正确地包含 gettext Header。完成该任务的最简单的方法是使用 GLib 提供的可用 Header(在 Versions 2.4 及更高版本中可用):
|
这个 Header 为您提供了 _() 和 N_() 宏,用来标记可翻译的字符串,稍后您将看到。
现在,您必须以一种 gettext 可以识别并在运行时进行翻译的方式来标记用户可见的字符串。出于这两个目的,您可以使用 _() 宏,它是 gettext() 函数完整调用的简短别名。
gettext() 函数查找消息目录中提供的字符串,以判断对于当前语言,是否存在一个经过翻译的合适的版本。如果存在,它会返回翻译结果;否则,它会返回原始字符串。当您为源代码进行翻译准备工作时,在扫描过程中将单词 gettext 作为标记,以便提取要翻译的消息并将其放置到单独的文件中。
认识到了这一点,您就可以开始以不同的语言进行表达了。在程序开始执行之前,您必须初始化 gettext:
|
现在,您可以使用 gettext() 调用来替换所出现的每个可以翻译的字符串。因此,下面的代码行形式:
|
变为:
|
这就是与此有关的全部内容,其中有两点例外之处。一个是不能在静态字符串中使用 gettext(),因为它是一个函数。在这种情况下,可以使用 N_() 宏,它不进行任何扩展,但会被作为对翻译内容进行标记的关键词。稍后在需要使用的地方,可以和前面一样使用 _()。因此:
|
另一个例外是包含某个数值变量的情况,如检索的文件的数目。在这种情况下,可以使用 ngettext() 函数,它能够理解复数。GNU gettext 库手册中包含了该函数的细节信息,以及关于 gettext() 函数的使用和操作的细节信息。
最后,请正确地选择哪些内容应该翻译,哪些内容不应该翻译。通常,所有用户可见的字符串都是翻译工作的候选对象。然而,对于调试信息和其他面向开发人员的信息,可以保留其中的部分或所有内容不进行翻译,以使得您自己和其他开发人员能够理解并在源代码中对其进行查找。FooWidget 便是这种方式的一个示例(请参见下面的“自定义小部件”),它包含了一个模拟的调试模式,在该模式中 RTL 或者 LTR 标记都没有进行翻译。
与此类似,避免翻译那些不是真正的单词的内容。例如,不要翻译 TCP/IP 状态标记,即使它们最初来自于英语单词。这类错误几乎随处可见,例如,在 Microsoft Windows 的网络工具中,类似 SYN_ACK 的内容被翻译 为毫无意义的波兰语 ZGODN_POTW。其结果是所有的人,包括说本族语的人,都被弄糊涂了,感到无法理解,甚至在 Internet 上查阅这样的信息。
自定义小部件
提供(或不提供,在合适的情况下)经过翻译的字符串是整个工作中重要的部分。其他的部分则是能够正确地显示这些字符串。要实现这个目标,需要您的应用程序能够处理文本方向为 RTL 的区域设置,而不是通常的英语中从左到右 (LTR) 的文本。因为这些区域设置中的文本是从右到左的,所以必须对 GUI 进行逻辑镜像(请参见图 1)。
图 1. 使用阿拉伯语运行的 GTK+ 应用程序
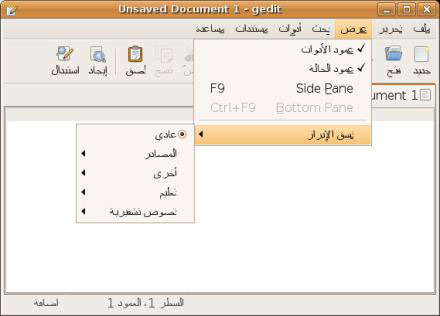
幸运的是,在百分之九十九的情况下,您几乎不用做任何事情 就可以启用这种模式。GTK+ 对这些工作进行自动处理,此外,由于布局代码根据小部件之间的逻辑关系而不是硬编码的像素座标进行操作。
即使您创建自定义的小部件,通常无需进行任何工作就可以实现对 RTL 区域设置的支持。只要您的小部件是其他小部件混合而成的,那么 GTK+ 中的布局逻辑将生效并完成正确的工作。真正需要您考虑本文方向的唯一情况是,您的小部件包含无法自动地进行镜像的自定义绘制代码,或者包含依赖于文本方向的其他逻辑。
作为示例,我包含了一个模拟的 FooWidget 应用程序,它并不完成任何特别有价值的工作,但是它可以对文本方向起作用并设置适当的消息。真正需要的只是使用 gtk_widget_get_direction() 进行简单的检查。因此,对于 FooWidget,下面代码中的技巧位于它的 _init() 函数中:
|
正如您所看到的,对用户的区域设置进行调整是非常简单的,并且仅依赖于您的小部件的复杂程度。如果您所完成的工作比较复杂,那么相应的代码可能会有些棘手。但是对于大多数用户,确保正常运行所需的工作仅包括简单的检查和直接的更改,如使用加法代替减法。
|
最后的说明
本文篇幅有限,无法详细地说明有关国际化的所有内容。特别是,本文没有涉及 Pango 的使用。幸运的是,如果您不打算编写很多的自定义小部件,那么您就不需要经常使用 Pango,并且大多数人也不需要这样做。然而,如果您发现自己需要进行文本显示,那么请务必使用 Pango 函数来进行布局、测量以及表示文本。
本文没有涉及到的另一个重要的方面是与您的构建系统进行集成。这种集成区别很大,具体取决于您所使用的对象,但是您必须正确地集成国际化以确保您的翻译是最新的。一种可能是使用 GNU 自动工具,它具有对 GNU gettext 库和相关实用程序以及来自 GNU gettext 库和相关实用程序的内置支持。这在开放源码项目中特别重要,因为自动工具被认为是缺省的构建系统。然而,由于其灵活性和强大的表达能力,自动工具以违反国际化的相关问题而出名,但没有什么是不能克服的,只是这需要一些(或大量的)专业知识。当您发现自己孤立无助的时候,您可以询问 GTK+ 用户邮件列表中其他的用户(请参见参考资料部分)。可能有人曾经碰到过您所遇到的问题。
请阅读 GNU gettext 库手册。即使您不打算使用 gettext,至少可以阅读一下引言部分:它包含了大量的信息,详细地说明了如何以及为什么库中所完成的工作在很大程度上独立于您所使用的任何特殊工具。
|
结束语
您了解了与应用程序国际化相关的一些挑战和常见的问题,以及如何解决它们。您知道了建立可以识别和支持不同语言和文化的用户需求的 GUI 所需进行的工作。使用本文中包括的参考资料,您可以获得各种各样的工具,以便可以创建能更好地满足更多用户的需求的程序。
