OProfile for Linux on POWER 识别性能瓶颈
发表于:2007-05-25来源:作者:点击数:
标签:
级别: 初级 John Engel Linux 技术顾问, IBM 2005 年 6 月 27 日 了解关于 OProfile 的知识,学习如何在基于 IBM POWER 处理器、运行 Linux 的 服务器 上使用它。首先,阅读关于 OProfile 的概述,并了解它在 Linux on POWER 上的实现,然后跟随作者给出的两
John Engel
Linux 技术顾问, IBM
2005 年 6 月 27 日
了解关于 OProfile 的知识,学习如何在基于 IBM® POWER™ 处理器、运行 Linux™ 的服务器上使用它。首先,阅读关于 OProfile 的概述,并了解它在 Linux on POWER 上的实现,然后跟随作者给出的两个例子,学习如何在 Linux on POWER 平台上使用 OProfile 分析代码和结果。
简介
作为一名开发人员,在试图提高代码效率时,您可能发现性能瓶颈是您要面对的最困难的任务之一。代码分析(code profiling)是一种可以使这项任务变得更容易的方法。代码分析包括对那些表示运行系统上的某些处理器活动的数据样本进行分析。OProfile 为 POWER 上的 Linux 提供了这种解决方案。OProfile 被包含在最新的 IBM® 支持的 Linux for POWER 发行版本中:Red Hat Enterprise Linux 4 (RHEL4) 和 SUSE LINUX Enterprise Server 9 (SLES9)。本文将介绍 OProfile for Linux on POWER,并提供两个例子,演示如何使用它来发现性能瓶颈。
代码分析概述
OProfile for Linux on POWER 使用了一个内核模块和一个用户空间守护进程,前者可以访问性能计数寄存器,后者在后台运行,负责从这些寄存器中收集数据。在启动守护进程之前,OProfile 将配置事件类型以及每种事件的样本计数(sample count)。如果没有配置任何事件,那么 OProfile 将使用 Linux on POWER 上的默认事件,即 CYCLES,该事件将对处理器循环进行计数。事件的样本计数将决定事件每发生多少次计数器才增加一次。OProfile 被设计成可以在低开销下运行,从而使后台运行的守护进程不会扰乱系统性能。
OProfile 具有对 POWER4™、POWER5™ 和 PowerPC® 970 处理器的内核支持。PowerPC 970 和 POWER4 处理器有 8 个计数寄存器,而 POWER5 处理器有 6 个计数寄存器。在不具备 OProfile 内核支持的架构上使用的则是计时器(timer)模式。在这种模式下,OProfile 使用了一个计数器中断,对于禁用中断的代码,OProfile 不能对其进行分析。
OProfile 工具
与 OProfile 内核支持一起提供的还有一些与内核交互的用户空间工具,以及分析收集到的数据的工具。如前所述,OProfile 守护进程收集样本数据。控制该守护进程的工具称作 opcontrol。表 1 列出了用于 opcontrol 的一些常见的命令行选项。本文的后面还将描述 opreport 和 opannotate 这两个工具,它们都是用于分析收集到的数据的工具。在 OProfile 手册的第 2.2 节中,可以找到对所有 OProfile 工具的概述。(请参阅参考资料。)
RHEL4 和 SLES9 上支持的处理器事件类型是不同的,正如不同 POWER 处理器上支持的事件类型也会有所变化一样。您可以使用 opcontrol 工具和 --list-events 选项获得自己平台所支持的那些事件的列表。
表 1. opcontrol 命令行选项
| opcontrol 选项 |
描述 |
| --list-events |
列出处理器事件和单元屏蔽(unit mask) |
| --vmlinux=<kernel image> |
将要分析的内核镜像文件 |
| --no-vmlinux |
不分析内核 |
| --reset |
清除当前会话中的数据 |
| --setup |
在运行守护进程之前对其进行设置 |
| --event=<processor event> |
监视给定的处理器事件 |
| --start |
开始取样 |
| --dump |
使数据流到守护进程中 |
| --stop |
停止数据取样 |
| -h |
关闭守护进程 |
OProfile 例子
您可以使用 OProfile 来分析处理器周期、TLB 失误、内存引用、分支预测失误、缓存失误、中断处理程序,等等。同样,您可以使用 opcontrol 的 --list-events 选项来提供完整的特定处理器上可监视事件列表。
下面的例子演示了如何使用 OProfile for Linux on POWER。第一个例子监视处理器周期,以发现编写不当、会导致潜在性能瓶颈的算法。虽然这是一个很小的例子,但是当您分析一个应用程序,期望发现大部分处理器周期究竟用在什么地方时,仍可以借鉴这里的方法。然后您可以进一步分析这部分代码,看是否可以对其进行优化。
第二个例子要更为复杂一些 —— 它演示了如何发现二级(level 2,L2)数据缓存失误,并为减少数据缓存失误的次数提供了两套解决方案。
例 1: 分析编写不当的代码
这个例子的目的是展示如何编译和分析一个编写不当的代码示例,以分析哪个函数性能不佳。这是一个很小的例子,只包含两个函数 —— slow_multiply() 和 fast_multiply() —— 这两个函数都是用于求两个数的乘积,如下面的清单 1 所示。
清单 1. 两个执行乘法的函数
int fast_multiply(x, y)
{
return x * y;
}
int slow_multiply(x, y)
{
int i, j, z;
for (i = 0, z = 0; i < x; i++)
z = z + y;
return z;
}
int main()
{
int i,j;
int x,y;
for (i = 0; i < 200; i ++) {
for (j = 0; j " 30 ; j++) {
x = fast_multiply(i, j);
y = slow_multiply(i, j);
}
}
return 0;
}
|
分析这个代码,并使用 opannotate 对其进行分析,该工具使您可以用 OProfile 注释查看源代码。首先必须利用调试信息来编译源代码,opannotate 要用它来添加注释。使用 Gnu Compiler Collections C 编译器,即 gcc,通过运行以下命令来编译清单 1 中的例子。注意,-g 标志意味着要添加调试信息。
gcc -g multiply.c -o multiply
|
接下来,使用 清单 2 中的命令分析该代码,然后使用 CYCLES 事件计算处理器周期,以分析结果。
清单 2. 用来分析乘法例子的命令
# opcontrol --vmlinux=/boot/vmlinux-2.6.5-7.139-pseries64
# opcontrol --reset
# opcontrol --setup --event=CYCLES:1000
# opcontrol --start
Using 2.6+ OProfile kernel interface.
Reading module info.
Using log file /var/lib/oprofile/oprofiled.log
Daemon started.
Profiler running.
# ./multiply
# opcontrol --dump
# opcontrol --stop
Stopping profiling.
# opcontrol -h
Stopping profiling.
Killing daemon.
|
最后,使用 opannotate 工具和 --source 选项生成源代码,或者和 --assembly 选项一起生成汇编代码。具体使用这两个选项中的哪一个选项,或者是否同时使用这两个选项,则取决于您想要分析的详细程度。对于这个例子,只需使用 --source 选项来确定大部分处理器周期发生在什么地方即可。
清单 3. 对乘法例子的 opannotate 结果的分析
# opannotate --source ./multiply
/*
* Command line: opannotate --source ./multiply
*
* Interpretation of command line:
* Output annotated source file with samples
* Output all files
*
* CPU: ppc64 POWER5, speed 1656.38 MHz (estimated)
* Counted CYCLES events (Processor cycles) with a unit mask of
0x00 (No unit mask) count 1000
*/
/*
* Total samples for file : "/usr/local/src/badcode/multiply.c"
*
* 6244 100.000
*/
:int fast_multiply(x, y)
36 0.5766 :{ /* fast_multiply total: 79 1.2652 */
26 0.4164 : return x * y;
17 0.2723 :}
:
:int slow_multiply(x, y)
50 0.8008 :{ /* slow_multiply total: 6065 97.1332 */
: int i, j, z;
2305 36.9154 : for (i = 0, z = 0; i " x; i++)
3684 59.0006 : z = z + y;
11 0.1762 : return z;
15 0.2402 :}
:
:int main()
:{ /* main total: 100 1.6015 */
: int i,j;
: int x,y;
:
1 0.0160 : for (i = 0; i " 200; i ++) {
6 0.0961 : for (j = 0; j " 30 ; j++) {
75 1.2012 : x = fast_multiply(i, j);
18 0.2883 : y = slow_multiply(i, j);
: }
: }
: return 0;
:}
|
清单 3 中下面的几行将显示两个乘法函数中所使用的 CYCLES 数:
36 0.5766 :{ /* fast_multiply total: 79 1.2652 */
|
50 0.8008 :{ /* slow_multiply total: 6065 97.1332 */
|
您可以看到,fast_mulitply() 只使用了 79 个样本,而 slow_multiply() 使用了 6065 个样本。虽然这是一个很小的例子,在现实中不大可能出现,但它仍然足以演示如何剖析代码,并为发现性能瓶颈而对其进行分析。
例 2:发现二级数据缓存失误
这个例子比第一个例子要复杂一些,它需要发现二级(L2)数据缓存失误。POWER 处理器包含芯片二级缓存(on-chip L2 cache),这是邻近处理器的一种高速存储器。处理器从 L2 缓存中访问经常修改的数据。当两个处理器共享一个数据结构,并同时修改那个数据结构时,就有可能引发问题。CPU1 在它的 L2 缓存中包含数据的一个副本,而 CPU2 修改了这个共享的数据结构。CPU1 L2 缓存中的副本现在是无效的,必须进行更新。CPU1 必须花费大量步骤从主存中检索数据,这需要占用额外的处理器周期。图 1 展示了两个处理器,它们在各自的 L2 缓存中包含一个共享数据结构的一个副本。
图 1. 共享一个数据结构的两个处理器
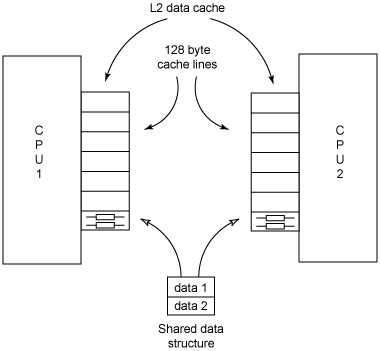
在这个例子中,您将查看这个数据结构(如清单 4 所示),并分析两个处理器同时修改这个数据结构时出现的情景)。然后观察数据缓存失误,并考察用来修正这个问题的两种解决方案。
清单 4. 共享的数据结构
struct shared_data_struct {
unsigned int data1;
unsigned int data1;
}
|
清单 5 中的程序使用 clone() 系统调用和 VM_CLONE 标志生成一个子进程。VM_CLONE 标志会导致子进程和父进程在同一个存储空间中运行。父线程修改该数据结构的第一个元素,而子线程则修改第二个元素。
清单 5. 演示 L2 数据缓存失误的代码示例
#include <stdlib.h>
#include <sched.h>
struct shared_data_struct {
unsigned int data1;
unsigned int data2;
};
struct shared_data_struct shared_data;
static int inc_second(struct shared_data_struct *);
int main(){
int i, j, pid;
void *child_stack;
/* allocate memory for other process to execute in */
if((child_stack = (void *) malloc(4096)) == NULL) {
perror("Cannot allocate stack for child");
exit(1);
}
/* clone process and run in the same memory space */
if ((pid = clone((void *)&inc_second, child_stack,
CLONE_VM, &shared_data)) < 0) {
perror("clone called failed.");
exit(1);
}
/* increment first member of shared struct */
for (j = 0; j < 2000; j++) {
for (i = 0; i < 100000; i++) {
shared_data.data1++;
}
}
return 0;
}
int inc_second(struct shared_data_struct *sd)
{
int i,j;
/* increment second member of shared struct */
for (j = 1; j < 2000; j++) {
for (i = 1; i < 100000; i++) {
sd->data2++;
}
}
}
|
使用 gcc 编译器,运行清单 6 中的命令不带优化地编译这个示例程序。
清单 6. 用于编译清单 5 中例子代码的命令
gcc -o cache-miss cache-miss.c
|
现在您可以用 OProfile 分析上述程序中出现的 L2 数据缓存失误。
对于这个例子,作者在一台 IBM eServer™ OpenPower™ 710 上执行和分析了这个程序,该机器有两个 POWER5 处理器,并运行 SLES9 Service Pack 1 (SLES9SP1)。将 --list-events 标志传递给 opcontrol,以判断是哪一个事件负责监视 L2 数据缓存失误。对于基于 POWER5 处理器的、运行 SLES9SP1 的系统,由 PM_LSU_LMQ_LHR_MERGE_GP9 事件监视 L2 数据缓存失误。如果您将样本计数设置为 1000,比如在这个例子中,那么 OProfile 将从每 1000 个硬件事件抽取一个样本。如果使用不同的平台,例如基于 POWER4 处理器的服务器,那么这样的事件也会有所不同。
使用 清单 7 中的命令分析这个例子代码,如下所示:
清单 7. 用来分析清单 5 所示例子中的 L2 数据缓存失误的命令
# opcontrol --vmlinux=/boot/vmlinux-2.6.5-7.139-pseries64
# opcontrol --reset
# opcontrol --setup –event=PM_LSU_LMQ_LHR_MERGE_GP9:1000
# opcontrol --start
Using 2.6+ OProfile kernel interface.
Reading module info.
Using log file /var/lib/oprofile/oprofiled.log
Daemon started.
Profiler running.
# ./cache-miss
# opcontrol --dump
# opcontrol -h
Stopping profiling.
Killing daemon.
# opreport -l ./cache-miss
CPU: ppc64 POWER5, speed 1656.38 MHz (estimated)
Counted PM_LSU_LMQ_LHR_MERGE_GP9 events (Dcache miss occurred for
the same real cache line as earlier req, merged into LMQ) with a
unit mask of 0x00 (No unit mask) count 1000
samples % symbol name
47897 58.7470 main
33634 41.2530 inc_second
|
在分析来自 opreport 的结果时,您可以看到,在函数 main() 和 inc_second() 中存在很多缓存失误。opreport 的 -l 选项将输出符号信息,而实质上输出的应该只是二进制映像名。同样,缓存失误的起因也是两个处理器修改一个共享的数据结构,这个数据结构大小为 8 字节,放在一个 128 字节的缓存行中。
消除数据缓存失误的一种方法是填充数据结构,使得它的每一个元素都存储在各自的缓存行中。清单 8 包含一个修改后的结构,其中有 124 字节的填充物。
清单 8. 带填充物的数据结构,每个元素放进不同的缓存行中
struct shared_data_struct {
unsigned int data1;
char pad[124];
unsigned int data1;
|
图 2 展示了在填充数据结构后,如何使得每个处理器上的每个数据元素都存储在各自的缓存行中。
图 2. 共享填充后的数据结构的两个处理器
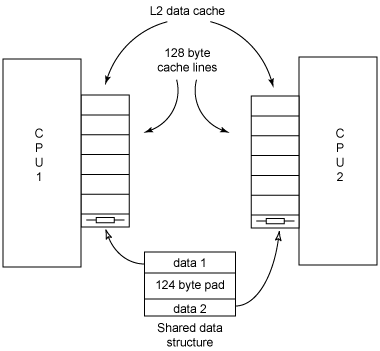
像前面那样重新编译该程序,但是这一次使用修改后的数据结构。然后使用 清单 9 中的命令再次分析结果。
清单 9. 填充数据结构后用于 profile L2 数据缓存失误的命令
# opcontrol --vmlinux=/boot/vmlinux-2.6.5-7.139-pseries64
# opcontrol --reset
# opcontrol --setup –event=PM_LSU_LMQ_LHR_MERGE_GP9:1000
# opcontrol --start
Using 2.6+ OProfile kernel interface.
Reading module info.
Using log file /var/lib/oprofile/oprofiled.log
Daemon started.
Profiler running.
# ./cache-miss
# opcontrol --dump
# opcontrol -h
Stopping profiling.
Killing daemon.
# opreport -l ./cache-miss
error: no sample files found: profile specification too strict ?
|
Opreport 表明,由于没有发现抽样数据,所以可能存在错误。然而,随着对共享数据结构的修改,这是可以预期的,因为每个数据元素都在自己的缓存行中,所以不存在 L2 缓存失误。
现在可以考察 L2 缓存失误在处理器周期上的代价。首先,分析使用未填充的原有共享数据结构的代码(清单 4)。您将进行抽样的事件是 CYCLES。使用 清单 10 中的命令针对 CYCLES 事件分析这个例子。
清单 10. 用于 profile 清单 5 所示例子中处理器周期数的命令
# opcontrol --vmlinux=/boot/vmlinux-2.6.5-7.139-pseries64
# opcontrol --reset
# opcontrol --setup –event=CYCLES:1000
# opcontrol --start
Using 2.6+ OProfile kernel interface.
Reading module info.
Using log file /var/lib/oprofile/oprofiled.log
Daemon started.
Profiler running.
# ./cache-miss
# opcontrol --dump
# opcontrol -h
Stopping profiling.
Killing daemon.
# opreport -l ./cache-miss
CPU: ppc64 POWER5, speed 1656.38 MHz (estimated)
Counted CYCLES events (Processor cycles) with a unit mask of 0x00
(No unit mask) count 1000
samples % symbol name
121166 53.3853 inc_second
105799 46.6147 main
|
现在,使用 清单 11 中的命令分析使用填充后的数据结构的例子代码(清单 8)。
清单 11. 用于分析使用填充后的数据结构的例子中处理器周期数的命令
# opcontrol --vmlinux=/boot/vmlinux-2.6.5-7.139-pseries64
# opcontrol --reset
# opcontrol --setup –event=CYCLES:1000
# opcontrol --start
Using 2.6+ OProfile kernel interface.
Reading module info.
Using log file /var/lib/oprofile/oprofiled.log
Daemon started.
Profiler running.
# ./cache-miss
# opcontrol --dump
# opcontrol -h
Stopping profiling.
Killing daemon.
# opreport -l ./cache-miss
CPU: ppc64 POWER5, speed 1656.38 MHz (estimated)
Counted CYCLES events (Processor cycles) with a unit mask of 0x00
(No unit mask) count 1000
samples % symbol name
104916 58.3872 inc_second
74774 41.6128 main
|
不出所料,随着 L2 缓存失误数量的增加,处理器周期数也有所增加。其主要原因是,与从 L2 缓存取数据相比,从主存获取数据代价昂贵。
避免两个处理器之间缓存失误的另一种方法是在相同处理器上运行两个线程。通过使用 Cpu 相似性(affinity),将一个进程绑定到一个特定的处理器,下面的例子演示了这一点。在 Linux 上,sched_setaffinity() 系统调用在一个处理器上运行两个线程。 清单 12 提供了原来的示例程序的另一个变体,其中使用 sched_setaffinity() 调用来执行这一操作。
清单 12. 利用 cpu 相似性来避免 L2 缓存失误的示例代码
#include <stdlib.h>
#include <sched.h>
struct shared_data_struct {
unsigned int data1;
unsigned int data2;
};
struct shared_data_struct shared_data;
static int inc_second(struct shared_data_struct *);
int main(){
int i, j, pid;
cpu_set_t cmask;
unsigned long len = sizeof(cmask);
pid_t p = 0;
void *child_stack;
__CPU_ZERO(&cmask);
__CPU_SET(0, &cmask);
/* allocate memory for other process to execute in */
if((child_stack = (void *) malloc(4096)) == NULL) {
perror("Cannot allocate stack for child");
exit(1);
}
/* clone process and run in the same memory space */
if ((pid = clone((void *)&inc_second, child_stack,
CLONE_VM, &shared_data)) < 0) {
perror("clone called failed");
exit(1);
}
if (!sched_setaffinity(0, len, &cmask)) {
printf("Could not set cpu affinity for current
process.\n");
exit(1);
}
if (!sched_setaffinity(pid, len, &cmask)) {
printf("Could not set cpu affinity for cloned
process.\n");
exit(1);
}
/* increment first member of shared struct */
for (j = 0; j < 2000; j++) {
for (i = 0; i < 100000; i++) {
shared_data.data1++;
}
}
return 0;
}
int inc_second(struct shared_data_struct *sd)
{
int i,j;
/* increment second member of shared struct */
for (j = 1; j < 2000; j++) {
for (i = 1; i < 100000; i++) {
sd->data2++;
}
}
}
|
这个例子在同处理器上运行两个线程,共享数据结构存放在一个处理器上的一个 L2 缓存行中。这样应该可以导致零缓存失误。使用前面描述的步骤分析缓存失误,以验证在一个处理器上运行两个进程时,是否不存在 L2 缓存失误。对于数据缓存失误这个问题,第三种解决方法是使用编译器优化,这样可以减少缓存失误的数量。然而,在某些环境下,这不是一个合适的选择,您仍然必须分析代码,并对不良性能做出改正。
结束语
分析是开发过程中最困难的任务之一。为了使代码获得最佳性能,好的工具是必不可少的。OProfile 就是这样一种工具,目前它提供了针对 Linux on POWER 的分析功能。对于其他平台上的可以快速移植到 Linux on POWER 的 Linux,还有其他许多性能和调试工具。除了处理器事件的类型有所差别外,在基于 POWER 处理器的 Linux 平台上运行 OProfile 与在其他架构上运行 OProfile 是类似的。所以,如果在其他平台上使用过 OProfile,那么您应该在很短时间内就可以知道如何在 Linux on POWER 上运行 OProfile。
致谢
我要感谢 Linda Kinnunen,是她提供了文档模板并对本文进行了审校,我还要感谢 Maynard Johnson 对本文进行了技术上的审校。
原文转自:http://www.ltesting.net
| 




