




Java Content Repository API 简介
如果曾经试过开发内容管理应用程序,那么您应当非常清楚在实现内容系统时所遇到的固有难题。这个领地有点支离破碎,许多供应商都有自己的私有仓库引擎。这些困难恶化了这类系统的复杂性和可维护性、增强了厂商锁定、增加了企业市场中对传统系统长期支持的需要。随着企业 weblog 和电子企业文档管理的日益流行,对标准化内容仓库接口的需求比以往任何时候都更加显著。
Content Repository for Java Technology 规范是在 Java Community Process 中作为 JSR-170 开发的,它的目标是满足这些行业的需求。该规范在 javax.jcr 名称空间中提供了统一的 API ,允许以厂商中立的方式访问任何符合规范的仓库实现。
但是 API 标准化并不是 Java Content Repository(JCR)带来的惟一特性。JSR-170 的一个主要优势就是没有捆绑到任何特定的底层架构上。例如,JSR-170 实现的后端数据存储可以是文件系统、WebDAV 仓库、XML 支持的系统或者是 SQL 数据库。而且,JSR-170 的导出和导入功能允许集成人员在后端内容和 JCR 实现之间无缝地切换。最后,JCR 提供了简单的接口,可以将该接口放在各种现有的内容仓库之上,并同时标准化一些复杂的功能(例如版本管理、访问控制和搜索)。
在讨论 JCR 时,有几种方式可以采用。在这篇文章中,我从开发人员的角度来研究 JSR-170 规范所提供的特性,重点放在可用的 API 和接口上,这些接口允许程序员在设计内容应用程序时有效利用 JSR-170 仓库。作为一个假设的示例,我将为一个类似维京百科全书的、叫做 JCRWiki 的系统实现一个小小的后端,为二进制内容、版本管理、备份和搜索提供支持。我使用 Apache Jackrabbit(JSR-170 的开源实现)开发这个应用程序。
仓库模型
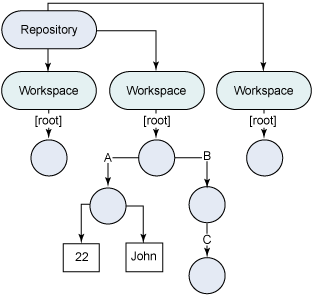
我先从对仓库模型的高级讨论开始,以便让您熟悉 JCR。仓库模型是简单的层次结构,看起来就像一个有 n 个分叉的树。它由单一内容仓库构成,有一个或多个工作区。(这篇文章中的讨论仅限制于单一工作区。)每个工作区都包含一个项目 树;项目既可以是节点 也可以是属性。节点可以有零个或多个子节点以及零个或多个相关属性,实际的内容保存在子节点和属性中。
每个节点都有且只有一个主节点类型。主节点类型定义了节点的特征,例如允许节点拥有的属性和子节点。除了主节点类型之外,节点还可以有一个或多个混合(mixin)类型。混合类型更像修饰器,向节点提供额外的特征。具体来说,JCR 实现可以提供三种预定义混合类型:
mix:versionable:允许节点支持版本管理mix:lockable:支持节点的锁定功能mix:referenceable:提供自动创建的jcr:uuid属性,给节点一个惟一可以引用的标识符
这个结构如图 1 所示。圆圈代表节点,矩形代表属性。请参见节点 A、B 和 C,它们都衍生自一个根节点。节点 A 有两个属性,即一个字符串 “John” 和一个整数 22。
图 1. 有多个工作区的仓库模型
预定义的节点类型
每个仓库都必须支持主节点类型 nt:base。仓库还可以支持其他许多公共节点类型:
nt:unstructured是最灵活的节点类型。它允许使用任意数量的子节点或属性,并且可以使用任意名称。这个节点类型表示 JCRWiki 的条目。
nt:file表示文件。它需要一个叫做jcr:content的单一子节点。这个节点类型表示 JCRWiki 条目中的图片和其他二进制内容。
nt:folder节点类型可以表示文件夹,就像常规的文件系统中的文件夹一样。
nt:resource通常表示文件的实际内容。
nt:version是支持版本管理的仓库所必需的节点类型。
整个节点类型的结构可以在 JSR-170 规范的 6.7.22.1 小节找到(请参阅 参考资料 获得链接)。
名称空间
仓库模型一个有用的却经常被忽视的特性就是它对名称空间 的支持。名称空间防止不同来源和不同应用程序域之间的项目和节点类型的命名冲突。名称空间被定义为带有一个前缀,中间用一个 : (冒号)分隔。在这篇文章的教程中,已经遇到了一些名称空间:jcr 用于 JCR 的内部属性,mix 用于混合类型,nt 用于节点类型。在 JCRWiki 中,所有的数据都将使用 wiki 名称空间。
|
安装 JCR
在编写这篇文章的时候,Apache Jackrabbit(即 Apache 基金会的 JSR-170 的开源实现)的发行版已经到了版本 1.0。编译好的字节码 JAR 可以直接从 Jackrabbit Web 站点下载(请参阅 参考资料)。虽然 Jackrabbit can 仍然可以用 SVN 从源代码进行编译,但是 Jackrabbit 库已经非常稳定,不再需要每夜构建(nightly builds)技术。这一节将提供尽可能快地安装 JCR 实现并运行它的详细说明。
需要的库
要使用和运行这篇文章中的示例,请将下面这些库放在类路径中:
jackrabbit-core:针对 JSR-170 的 Jackrabbit 内容仓库核心实现和来自 Apache 的公共实用代码。
commons-collections:包含强大数据结构的框架,该框架可以加快 Java 应用程序的开发。
concurrent:这个库提供通常在 Java 并发编程中会遇到的工具类的标准化的、有效率的版本。
derby:一个 Apache 数据库子项目,它提供完全用 Java 语言实现的关系数据库。
jcr:一组符合 JSR-170 规范的接口。
log4j:运行时日志库。
lucene:高性能的全功能文本搜索引擎库。
slf4j(针对 Java 的简单日志 Facade):目的是充当不同日志 API 的简单 facade,允许用户在部署时插入需要的实现。
xerces:高级 XML 解析器,支持 SAX 版本 2、DOM 1 级和 SAX 版本 1 API。
如果用 SVN 构建 Jackrabbit,那么所有这些 JAR 文件都会在 Jackrabbit 构建过程中被下载,并位于 Maven 的缓存目录中。在 Linux 下,这些 JAR 位于主目录的 .maven 目录下。如果使用二进制构建,那么只需要从它们各自的 Web 站点下载其二进制版或浏览 Jackrabbit Web 站点的 “First Hops with Jackrabbit” 即可,那里会提供到所有这些资源的直接链接。在 JSR-170 规范的下载中还有一个 jcr-1.0.jar,在 Java 社区进程的 Web 站点上也可以找到它。
|
手工配置
JSR-170 没有确切地指定应当如何获得初始的 Repository 对象;这被留作每个仓库厂商的实现细节。但是,在应用程序中最好使用 JNDI 或其他容器环境中的配置机制,这样可以保持 JSR-170 的实现相对独立于对 Jackrabbit 的直接依赖项。虽然这一策略在初始配置期间造成了额外的复杂性,但它提供了跨不同 JSR-170 实现的更好的移植性。要想获得一个移植性虽然差但得到了简化的配置,可以使用自动配置,详细内容在这篇文章后面部分介绍。
在手工配置中,可以将 JNDI 与配置文件(叫做 repository.xml,以编程方式载入)结合使用来得到仓库。
仓库配置
第一步,也是最容易的一步,就是为 Jackrabbit 创建 repository.xml 文件。这个配置文件实现了许多重要任务。这些任务包括:指定底层的后端存储、访问控制机制、可用的工作区、版本管理系统和搜索子系统。清单 1 提供了一个示例:
清单 1. 示例 repository.xml 配置文件
|
这个配置使用本地文件系统来保存仓库数据,用 SimpleAccessManager 进行访问控制。文件剩下的部分基本是自解释的,将它们原样复制到自己的仓库目录中即可。
安全性配置
使用 JASS 配置文件 jaas.config(存放在项目的根目录中),可以提供初步的安全性。清单 2 提供了一个示例:
清单 2. 示例 JAAS 配置
|
仓库初始化代码
清单 3 描述的包可在初始化仓库时使用:
清单 3. 手工配置的初始化 import 语句
|
要得到 Repository 对象,请将 configFile 变量设置成指向 repository.xml 文件,将 repHomeDir 变量设置成指向仓库所在的本地文件系统目录。当结合 RegistryHelper 使用 JNDI 时,获得仓库非常简单,如清单 4 所示:
清单 4. 用 JNDI 获得 repository 对象
|
接下来,用 SimpleCredentials 获得 Session 对象。在这个实现中,SimpleCredentials 接受所有用户名。替代的 JCR 实现可以提供更复杂的认证机制,可以连接到 LDAP 服务器或外部数据库来提供凭据信息。(身份验证和访问控制的完整功能超出了本文的范围。要获得有关的更多信息,请参阅 JSR-170 规范的 6.9 小节。)
Session 对象为程序员提供了一个临时的存储层,它非常像传统的对象关系映射工具中可以看到的层,而且还可以将它看作到特定工作区的连接。它允许客户访问绑定到这个会话的任何节点或属性。通过会话,可以得到工作区,再从工作区得到根节点。所有这些步骤都是在清单 5 的简短代码片段中完成的:
清单 5. 获得工作区和根节点
|
使用会话、工作区和根节点引用,现在可以通过不同的抽象层访问仓库的特性。最后,为了验证仓库已经成功获得初始化,可以用 rn.getPrimaryNodeType().getName() 输出根节点的名称。这应当形成以下输出:
|
因为正在使用 JAAS,所以请记得将 -Djava.security.auth.login.config==jaas.config. 以 Java JVM 参数的形式包含进来。
JCRWiki 名称空间
在这个练习中,所有的 JCRWiki 内容都放在 wiki 名称空间下。为了让仓库识别这个名称空间,必须在初始化时注册名称空间,如下所示:
|
恭喜!仓库的手工配置现在完成了。
|
自动配置
Jackrabbit 实现还提供了一个 TransientRepository 类,这个类来自其核心 API,可以在启动第一个会话时自动初始化内容仓库,并在最后一个会话关闭时停止使用仓库。对于简单的独立应用程序,使用 TransientRepository 可以极大地简化仓库的配置,但要以 JSR-170 的移植性作为代价。
TransientRepository 自动创建 repository.xml 和仓库文件夹。它还在内部提供了处理身份验证和安全性的 SimpleAccessManager。
自动配置需要使用如图 6 所示的初始化 import 语句。与手工配置相比,所有的 JNDI 引用都被删除了。在 RegistryHelper 的位置换上了 TransientRepository。
清单 6. 自动配置的 import 语句
|
因为 TransientRepository 为您执行了初始化,所以获得仓库非常简单,如清单 7 所示:
清单 7. 用 TransientRepository 获得仓库、工作区和根节点
|
像手工配置时一样,所有的 JCRWiki 内容都放在 wiki 名称空间下:
|
恭喜!仓库的自动配置现在完成了。
|
JCRWiki 的设计策略
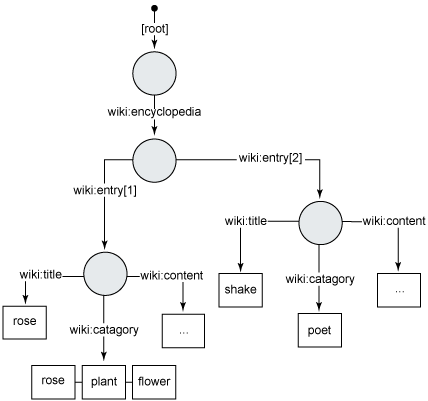
现在看一下 JCRWiki 仓库的整体内容层次结构。在示例中,要创建两个实体 “rose” 和 “Shakespeare”,它们都是 nt:unstructured 类型的。根据设计合同,每个百科全书条目都要有三个属性:条目的标题、条目的内容以及多值分类属性(如果条目有多个分类)或单值分类属性(如果条目只有一个分类)。多值属性在编程上表现为一组数值。
图 2 描绘了 JCRWiki 设计策略的图示:
图 2. JCRWiki 拓扑的高层图示
|
JCRWiki 功能
没有内容的仓库没什么用处。这一节将演示 JSR-170 提供的基本内容操纵功能,并描述一些更高级的、可选的仓库特性,例如版本管理和导入导出 XML 内容。
添加内容
从清单 8 开始,向仓库添加内容节点,让它看起来像图 2 中的 JCRWiki 拓扑:
清单 8. 将内容添加到 JCR 仓库中
|
默认情况下,Jackrabbit 的节点被设置为 nt:unstructured。注意,“rose” 的分类属性是多值的。上面代码段的最后一行代码将保存会话。添加和设置节点以及节点属性只能修改临时的会话存储层。要将这些变化保持到仓库中,则必须用 session.save() 保存会话。可以在目标节点上调用 Node.remove() 来删除节点。
存取内容
JSR-170 提供了两种存取内容的方法:遍历 存取和直接 存取。遍历存取包括用相对路径在内容树中进行遍历,直接存取允许用绝对路径直接跳到节点,如果节点是可以引用的,则用 UUID 直接跳到节点。因为两种存取之间存在相似性,所以我在这篇文章只侧重于遍历存取。
从任何 Node 对象及其方法 Node.getNode()、Node.getProperty() 都可以进行遍历存取。通过使用 JCRWiki 拓扑,可以用以下代码从根节点获得 encyclopedia 节点:
|
可以进一步通过遍历得到属性。例如,在根节点向下的 “rose” 百科全书节点条目中,假设以前知道 JCRWiki 拓扑,那么可以像这样通过遍历得到属性:
|
请注意,您是通过 wiki:entry[1] 进行遍历的。当有同名的多个同级节点时,可以用下标区分出想要的同级节点。在 JCR 中,对同级节点的索引是从 1 而不是 0 开始的。而且,索引的顺序是在通过 Node.getNodes() 得到的迭代器中返回的节点的顺序。
然后,可以通过获取 NodeIterator(它返回特点节点的子节点)来浏览所有 JCRWiki 条目,如清单 9 所示:
清单 9. 浏览内容仓库
|
因为分类属性可以是多值的也可以是单值的,所以要用 try-catch 语句检查它。如果对多值属性调用 getValue(),就会抛出 ValueFormatException。一般来说,直接存取和遍历存取都需要知道内部节点的结构。所以让我们来看一种更具表现力的存取节点的方式:使用搜索。
用 XPath 搜索内容
正如已经看到的,遍历存取和直接存取都需要知道图书的位置。获得特定条目的更好方式是通过 JCR 的 XPath 搜索工具。因为从树形结构来看,工作区模型非常类似于 XML 文档,所以 XPath 是查找节点的理想语法。XPath 查询是通过 QueryManager 对象执行的。查询的过程与通过 JDBC 存取记录类似,如清单 10 所示:
清单 10. 用 XPath 搜索内容
|
createQuery() 的第二个参数指定所使用的查询语言。JRC 实现可以另外选择为 SQL 语法支持 Query.SQL。也可以执行更复杂的查询。例如,可以查询的内容中包含单词 rose 的所有条目:
|
用 XML 导入和导出内容
JSR-170 为了确保跨 JCR 实现的移植性已经做了许多工作。它促进移植性的方式之一就是使用标准的 XML 导入和导出特性。通过使用这些工具,符合规范的供应商仓库内容可以很容易地转移到另一个符合规范的供应商仓库。使用 XML 进行序列化的另一个优势是:可以用传统的 XML 解析工具操纵导出的仓库。只要用清单 11 的三行代码就可以执行导出:
清单 11. 导出数据
|
然后可以把生成的 XML 文件转移给另一个新仓库,如清单 12 所示:
清单 12. 转移数据
|
添加二进制内容
直到现在,一直都是用 StringValue 表示属性和节点。但是 JCR 还支持其他类型,包括布尔型和长整型。清单 13 演示了 JCR 中可使用的流类型,可在节点中保存二进制图片。在这个清单中,可将文件 rose.gif 作为元数据添加到 nt:file 节点中。文件数据本身被保存为 nt:resource 子节点。
清单 13. 添加二进制内容
|
在使用 MimeTable 类确定了内容类型之后,用 FileInputStream 装入文件。这个问题很简单,只要给 nt:resource 节点类型添加命名正确的属性即可,属性包含实际的文件数据。
版本管理
JSR-170 支持许多可选特性,包括访问控制、事务、锁定和版本管理。这些特性本身都可以是个完整的主题,所以我必须简要地总结一下,只介绍它们当中最流行的那一个:版本管理。在最简单的情况下,只需将 mix:versionable 混合类型添加到任何节点,就可以执行版本管理。在节点上,可以用一组类似 CVS 操作的方法实现版本管理,如清单 14 所示:
清单 14. 版本管理方法
|
JCR 中的其他操作包括:更新、合并和恢复以前版本。要浏览指定节点的整个版本历史,可以通过清单 15 中的步骤进行:
清单 15. 浏览版本历史
|
使用 vi.skip(1) 最初看起来可能有点怪,但是如果看到了版本历史的内部保存机制,就应该很清楚这种用法了,版本历史的内部保存机制如图 3 所示:
图 3. 节点版本历史的结构化模型
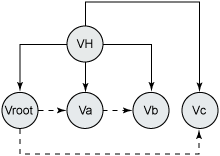
在节点的版本历史中,每个版本都保存为版本历史的一个子版本,而且包含指向后续版本的引用。在图 3 中,版本 Vb 是版本 Va 的后续,版本 Vc 和 Va 是 Vroot 的后续,Vroot 是版本图的开始。Vroot 是自动创建的子节点,是版本图的起点,它不包含任何状态信息。所以,当应用程序在版本历史中遍历时,Vroot 被跳过。
|
结束语
本文提供了对 JSR-170 规范所提供特性的广泛介绍。在 2005 年 6 月 17 日通过的规范的最终发行版中,已有两个商业实现:Day Software 的 CRX 和 Obinary 的 Magnolia Power Pack。JSR-170 的引入也导致了企业开源门户和内容管理系统(如 Magnolia 和 eXo 平台)的增多。最重要的是,JSR-170 拥有来自行业领导者(包括 SAP AG、Macromedia 和 IBM)的强大支持,从而在企业阵营建立起了它自己的应用和重要性。就像对象关系映射框架改变了数据库编程一样,JCR API 也有可能极大地改变我们思考和开发内容应用程序的方式。
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-

