




Java 技术,IBM 风格: 监视和判断问题
随着时间的推移,IBM 为它的 Java 运行时实现开发了许多监视和问题诊断设施。利用这些工具,IBM 支持团队、Java 应用程序开发人员和生产操作人员可以诊断和解决在 Java 开发中遇到的问题。
本文讨论三种主要的设施,因为它们是在 Java 技术的 IBM 实现的最新版本中实现的:跟踪引擎、转储引擎和 DTFJ 工具 API。它们都有助于 Java 开发人员判断问题的根源。
|
||||||||||
跟踪引擎
在判断软件的问题时,跟踪信息是一种强大的工具:可以使用它有效地研究问题场景(比如功能性错误、竞争状态和性能问题),而且它非常有助于了解程序的流程。
IBM 在 SDK 1.2.2 中首次在它的 Java 运行时实现中引入了跟踪引擎,帮助 IBM 开发团队诊断 Java 虚拟机(JVM)的缺陷。这种跟踪设施的目的是为虚拟机本身提供一个低开销、高性能、可配置的跟踪机制。在后续的版本中,进行了显著的调整和改进;IBM SDK 的当前版本提供一个高性能的引擎,它能够捕捉 JVM、Java Class Libraries(JCL)和部署到运行时中的任何 Java 应用程序代码的跟踪数据,而不需要任何其他设施。
|
激活和控制跟踪
可以通过多种机制激活和控制跟踪引擎:
- 通过命令行选项
-Xtrace - 使用跟踪属性文件
- 通过
com.ibm.jvm.TraceAPI,使用 Java 代码进行动态控制 - 使用跟踪触发器事件
- 从外部代理使用基于 C 的 JVM RAS Interface(JVMRI)
控制跟踪的主要方法是使用命令行选项 -Xtrace,或者在选项集比较长或复杂的情况下,使用可选的跟踪属性文件。
-Xtrace 选项由一系列标志或标志-值对组成,这些设置用来决定跟踪应该写到 stderr、内部缓冲区还是二进制文件;是启用方法跟踪、JVM 跟踪,还是两者都启用;应该跟踪哪些跟踪点;是跟踪对跟踪点的任何修改,还是在发生事件时触发转储。
激活跟踪的基本知识
在使用 IBM 的跟踪设施时,需要决定的第一件事是应该将跟踪输出定向到哪个目的地。表 1 简要描述这些目的地以及将多少跟踪点数据发送给它。例如,print 将所有跟踪数据定向到 stderr,minimal 将每个跟踪点的数据子集定向到内存缓冲区,然后又可以使用 output 选项将这些缓冲区中的数据捕捉到文件中。
表 1. 跟踪目的地
| 关键字 | 功能 |
|---|---|
minimal |
将选择的跟踪点(只有标识符和时间戳)定向到核心缓冲区。不记录相关联的跟踪数据。 |
maximal |
将选择的跟踪点(标识符和时间戳以及相关联的数据)定向到核心缓冲区。 |
count |
统计在 JVM 的生命期内调用选择的跟踪点的次数。 |
print |
将选择的跟踪点定向到 stderr,不进行缩进。 |
iprint |
将选择的跟踪点定向到 stderr,进行缩进。 |
external |
将选择的跟踪点定向到 JVMRI 监听器。 |
exception |
将选择的跟踪点定向到为异常保留的核心缓冲区。 |
应该将每个关键字的值设置为所需的跟踪点。例如:
-Xtrace:maximal=all将来自所有 JVM 跟踪点的所有信息记录到内部回绕缓冲区中。
-Xtrace:iprint=awt将所有 JVM 内部 AWT 跟踪点记录到stderr,在进入和退出时进行缩进。
-Xtrace:iprint=mt激活方法跟踪并将输出发送到stderr,进行缩进。
仅仅使用表 1 中的选项并不会生成任何输出;必须单独提供要跟踪的方法名。注意,IBM Diagnostics Guide 的第 32 章 “Tracing Java applications and the JVM” 详细讨论了所有跟踪选项(见 参考资料)。
将跟踪数据放进内部缓冲区中
使用存储内缓冲区进行跟踪是非常高效的,因为在探测到问题或者使用 API 将缓冲区写入文件之前,不执行显式的 I/O。缓冲区被分配给每个线程,这防止线程之间发生冲突并防止各个线程的跟踪数据相互干扰。例如,如果某个线程没有被调度,当转储缓冲区时它的跟踪信息仍然是可用的。
要查看跟踪数据,必须转储缓冲区并进行格式化。当发生以下情况时,自动进行缓冲区的转储:
- 发生未被捕捉的 Java 异常
- 发生操作系统信号或异常
- 调用
com.ibm.jvm.Trace.snap()Java API - 调用 JVMRI
TraceSnap函数
将跟踪数据放进文件中
可以连续地将跟踪数据写到文件中,作为存储内跟踪的扩展;但是在这种情况下不是为每个线程分配一个缓冲区,而是至少分配两个。当一个跟踪缓冲区满了时,将它写到文件系统中,这使线程能够连续运行。根据跟踪量、缓冲区大小和输出设备的带宽,可以将多个缓冲区分配给给定的线程,从而与生成跟踪数据的速度相匹配。
要将 minimal 或 maximal 跟踪选项的输出写到文件中,应该使用 output 关键字,对于 exception 选项使用 exception.output 关键字:
-Xtrace:maximal=all,output=trace.out将跟踪数据写到文件 trace.out 中。-Xtrace:maximal=all,output={trace.out,5m}将跟踪数据写到文件 trace.out 中,当文件达到 5MB 时进行回绕。-Xtrace:maximal=all,output={trace#.out,5m,5}将跟踪数据依次写到 5 个文件中,每个文件 5MB,#用文件的序号代替。在这个示例中,创建文件 trace0.out 到 trace4.out,每个文件包含最近的 5MB 跟踪数据。当 5 个文件都填满时,JVM 依次覆盖 trace0.out 到 trace4.out。这个选项可以创建的最大文件数是 36 个,#字符被替换为 0 到 9,然后是 A 到 Z。
还可以在文件名中进行以下替换:
%p:Java 进程的 ID。%d:yyyymmdd 格式的当前日期。%t:hhmmss 格式的当前时间。
对跟踪文件进行格式化
跟踪格式化器(trace formatter) 是一个可以在任何平台上运行的 Java 程序,可以对来自任何平台的跟踪文件进行格式化。IBM SDK 在 core.jar 中提供了这个格式化器,它还需要一个称为 TraceFormat.dat 的文件,其中包含格式化模板。这个文件在 jre/lib 中。可以用以下命令行启动跟踪格式化器:
|
在这里,com.ibm.jvm.format.TraceFormat 是跟踪格式化器类,input_file 是要进行格式化的二进制跟踪文件的名称,output_file 是可选的输出文件名。如果没有指定输出文件,那么默认的输出文件名是输入文件名加上 .fmt。
动态记录器
IBM VM 跟踪设施包含一个动态记录器(flight recorder),它连续地将来自关键跟踪点子集的数据捕捉到内存缓冲区中。当出现运行时问题时捕捉这些缓冲区,可以用来诊断问题并分析 VM 的历史。VM 初始化过程用一小组跟踪点启动跟踪,这些跟踪点被捕捉到回绕式存储内缓冲区中。可以使用这些信息初步诊断 Java 运行时中的任何问题,并确保 -verbose:gc 选项提供的数据子集总是可用的。垃圾收集数据也出现在 Java 转储文件中。
内部的动态记录器使用一个命令行选项:
|
如果在命令行上指定 -Xtrace,或者在属性文件中设置它,那么清除激活的跟踪点集。
方法跟踪
可以利用 Java 方法跟踪来跟踪每个线程对方法的调用,包括进入方法和退出方法,这种跟踪针对 Java 运行时的 IBM 实现上运行的任何代码进行。这不需要对 Java 代码进行任何手工处理,可以使用它跟踪 JCL、第三方包或应用程序代码。
方法跟踪功能尤其适合调试发生竞争状态和在方法之间传递了不合适的参数而导致异常的情况。由于跟踪时间戳具有毫秒级的精度,方法跟踪还可以用来调试性能问题。
在命令行上调用方法跟踪的办法是,添加 methods 关键字标志并将 mt 设置给目的地关键字之一(maximal、minimal、print)。methods 关键字允许按照类、方法名或这两者选择要跟踪的方法。可以使用通配符和取反操作符 ! 建立复杂的选择条件。例如:
-Xtrace:print=mt,methods={*.*,!java/lang/*.*}:对于除了java.lang包中的方法和类之外的所有方法和类,将方法跟踪写到stderr中。
-Xtrace:maximal=mt,output=trace.out,methods={tests/mytest/*.*}:对于tests.mytest包中的所有方法,将方法跟踪写到文件中。(注意,这个选项只选择要跟踪的方法。)
在发生跟踪事件时触发
IBM 跟踪引擎最强大的特性之一是它能够在发生跟踪事件时触发,这有助于创建目的明确的跟踪输出并减少产生的跟踪数据量。这会提高被调试的应用程序的性能(由于开销大大降低了)和解释数据的速度(由于多余的数据减少了)。
跟踪引擎能够在任何给定的跟踪点上触发,包括 VM 内部的跟踪点或 Java 方法,而且在发生事件时可以执行许多操作,见表 2:
表 2. 跟踪引擎操作
| 关键字 | 功能 |
|---|---|
suspend |
暂停所有 跟踪(特殊跟踪点除外)。 |
resume |
恢复所有 跟踪(由 resumecount 属性和 Trace.suspendThis() 调用暂停的线程除外)。 |
suspendthis |
增加这个线程的暂停计数。非零的暂停计数会停止这个线程的所有跟踪。 |
resumethis |
减少这个线程的暂停计数(如果这个值大于零的话)。如果暂停计数到达零,那么这个线程的跟踪就会恢复。 |
sysdump |
生成非破坏性的系统转储。 |
javadump |
生成 Java 转储。 |
heapdump |
生成堆转储。 |
snap |
将所有激活的跟踪缓冲区写到当前工作目录中的一个文件中。 |
可以使用 trigger 命令行关键字激活触发跟踪,这个关键字决定在发生事件时执行表 2 中的哪些操作。注意,触发选项控制其他跟踪属性已经选择的跟踪数据是正常生成,还是被阻塞。
使用以下格式指定方法事件上的触发:
|
当进入与 method spec 匹配的任何方法时,执行 entry action。当退出方法时,执行 exit action。如果指定了 delay count,那么只有当进入和退出的次数大于 delay count 时才执行 entry action 和 exit action。如果指定了 match count,那么操作的执行次数不超过这个值。请考虑以下示例:
|
这在第一次(而且只在第一次)调用 StackOverflowError 方法时(进行调用的是 <clinit> 方法),创建一个非破坏性的系统转储。
可以使用 suspend 和 resume 选项并结合 resumecount 或 suspendcount 关键字来暂停和恢复单独的线程或所有线程:
|
这些选项在调用 HelloWorld.main() 时开始跟踪所有线程,在 HelloWorld.main() 返回时停止跟踪。这实际上意味着在 Java 运行时启动时不进行跟踪,只在 HelloWorld 应用程序运行期间生成跟踪数据。
用跟踪引擎能够实现什么?
可以使用跟踪引擎为 Java 运行时本身或其中运行的应用程序代码中的任何问题生成数据流或历史数据。这些历史数据加上转储引擎生成的状态数据能够帮助开发人员了解和调试许多问题。
|
转储引擎
Java 运行时的 IBM 实现中内置了转储引擎,它能够提供大多数必需的数据,帮助 IBM 支持团队对 Java 运行时本身或 IBM SDK 提供的 JCL 中的问题进行诊断。转储引擎的默认设置在发生特定事件时触发许多不同类型的转储,可以对这些转储进行后期处理来判断许多问题的原因。
还可以使用许多转储和事件来诊断 Java 应用程序中的问题,因为用来诊断 JCL 中的问题的过程同样可以用来诊断其他 Java 类中的问题。
转储类型
IBM 转储引擎可以生成 4 种类型的转储(在 z/OS® 上有 5 种),如果需要的话,还能够在单独的进程中执行一个工具。每个转储类型本身都是非破坏性的,但是如果是由故障事件(比如 SIGSEGV/GPF)造成的,就会变成破坏性的。表 3 描述可用的转储类型:
表 3. 转储类型
| 关键字 | 转储类型 | 说明 |
|---|---|---|
java |
Java 转储 | 包含环境、锁、线程堆栈和类信息的状态报告。 |
heap |
堆转储 | 这种转储包含 Java 堆上每个 Object 的大小和引用细节。 |
snap |
Snap 转储 | 写到文件中的跟踪缓冲区内容。 |
system |
系统转储 | 进程映像,采用操作系统的一般格式(核心文件、微转储或事务转储)。 |
ceedump |
CEEDUMP | z/OS 特有的线程堆栈和寄存器汇总文件。 |
tool |
工具代理 | 使用提供的命令行执行一个预定义的工具。 |
转储事件
IBM 转储引擎能够在发生表 4 中的事件时生成任何或所有类型的转储:
表 4. 事件类型
| 事件 | 说明 |
|---|---|
gpf |
发生未预料到的崩溃,比如 SIGSEGV 或 SIGILL。 |
user |
发生 SIGQUIT 信号(Windows 上的 Control+Break,Linux 上的 Control+\,z/OS 上的 Control+V)。 |
vmstart |
VM 完成初始化。 |
vmstop |
VM 将要关闭。 |
load |
装载了一个新类。 |
unload |
卸载了一个类装载器。 |
throw |
抛出了一个 Java 异常。 |
catch |
捕捉到了一个 Java 异常。 |
uncaught |
有一个 Java 异常未被应用程序处理。 |
thrstart |
启动了一个新线程。 |
thrstop |
停止了一个现有线程。 |
blocked |
一个线程被阻塞,进入监视器。 |
fullgc |
启动垃圾收集。 |
这些事件本身为指定何时生成每种转储提供了很大的灵活性,但是如果结合使用转储过滤器 的话,灵活性还会大大提高。可以在每种事件上添加一个过滤器,从而以更细的粒度控制何时创建转储。例如,可以在 throw、catch 和 uncaught 事件上添加异常名或错误名。
设置转储选项并修改默认设置
使用 -Xdump 命令行选项和一系列标志来设置各种转储选项。可以使用 -Xdump:what 查看默认的转储选项,见清单 1:
清单 1. -Xdump:what 输出
|
可以通过修改语法来添加其他转储。要在发生未捕捉的套接字异常时生成 Java 转储,使用以下语法:
|
要删除所有堆转储,使用以下语法:
|
使用转储引擎能够实现什么?
可以使用转储引擎的功能解决 IBM SDK 本身中的问题;更重要的是,可以利用它们解决 Java 应用程序中的问题。在发生 OutOfMemoryErrors 时能够生成 Java 转储文件和堆转储,因此能够诊断内存泄漏并分析任何大对象的堆栈。能够在发生其他异常时生成 Java 转储文件,因此能够使用转储中的线程堆栈数据来调试潜在的竞争状态。
另外,在发生各种事件时能够创建非破坏性的系统转储,这意味着可以使用 DTFJ API 研究在发生事件时 Java 应用程序的任何部分的状态。
|
Diagnostic Toolkit and Framework for Java
DTFJ API 是一个基于 Java 的 API,工具的编写者可以使用它访问关于 Java 进程的信息,这只需要有进程映像的快照(例如,系统转储),工具的编写者不需要了解各种系统转储格式以及 Java 对象和其他 Java 结构在内存中的布局方式。
正如前面提到的,Java 运行时的 IBM 实现能够使用跟踪或转储引擎创建非破坏性的系统转储。另外,还可以使用 com.ibm.jvm.Dump.SystemDump() 静态方法创建非破坏性的系统转储。还可以使用操作系统工具获得同样的结果,例如 AIX® 上的 gencore 或 Linux 上的 gcore。
创建非破坏性的系统转储使工具能够使用 DTFJ API 从正在运行的系统获得信息,还可以对发生故障和已经关闭的系统进行分析。
体系结构
DTFJ API 是一个分层的接口,它独立于运行时实现:这个 API 本身可以用于多种操作系统和硬件平台、多种虚拟机实现和多种语言。DTFJ API 中包含的基本扩展集针对的是 Java 运行时,因此使工具的编写者能够了解和探察 JVM 数据结构,Java 运行时的 IBM 实现附带的 DTFJ 实现能够提供关于这些运行时中的数据结构的信息。
这个 API 本身受到了 Reflection API 的深刻影响,并结合了 Java 进程的一个层次化视图,这个视图使用 Iterator 访问从高层对象到更特定对象的各个对象。这提供了许多可用的数据对象,从进程的 Image 到单独的 JavaField 和 JavaMethod 对象,可以探察这些对象来获得在建立系统转储时它们包含的数据。图 1 给出了 DTFJ API 可以了解和探察的一些数据对象:
图 1. DTFJ 数据对象概述
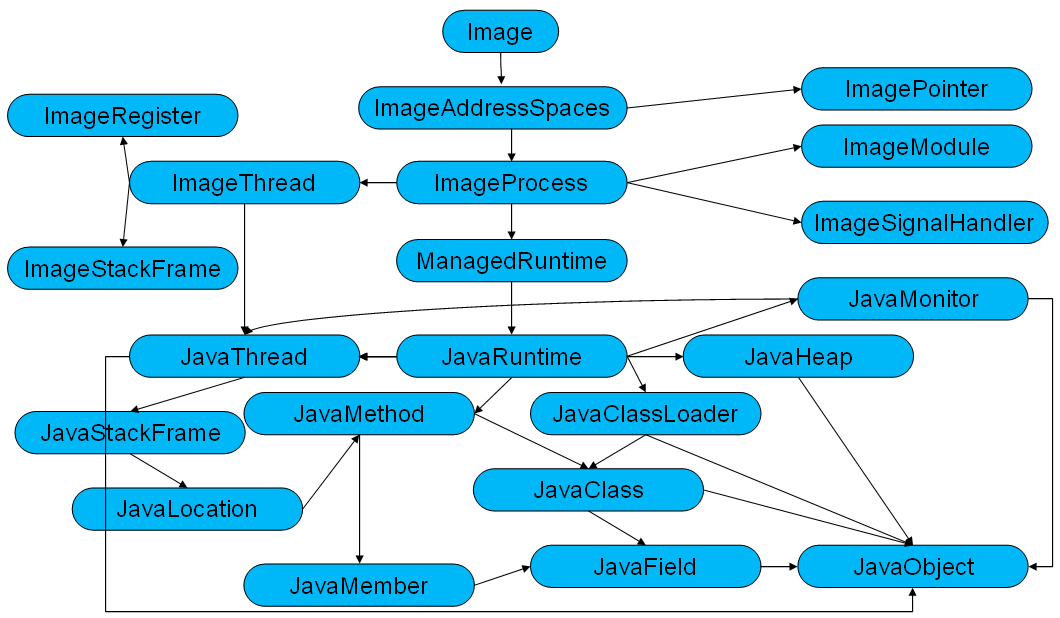
运行 JExtract
因为各种操作系统生成不同的系统转储格式,而且随着时间的推移内部 Java 运行时数据结构可能会发生一些必要的改变,所以需要对系统转储运行一个称为 JExtract 的实用程序,然后才能使用 DTFJ API 访问系统转储。这个操作需要由生成系统转储时运行的相同 Java 运行时版本来执行,而且应该在同一个系统上执行。
JExtract 实用程序了解系统转储和 Java 运行时内部数据结构的格式。它利用这一知识创建一个 XML 描述文件,这个文件为系统转储文件提供索引,指出各个数据结构的位置。然后,DTFJ 就可以结合使用系统转储和 JExtract 生成的 XML 文件来生成工具所请求的信息。
尽管 JExtract 是系统转储的后处理程序,但是可以使用转储引擎的 tool 选项在创建系统转储之后自动调用 JExtract。例如,为了在发生 OutOfMemoryErrors 时创建系统转储,使用以下语法:
|
可以使用 DTFJ API 实现什么?
可以使用 DTFJ API 访问系统转储中的大量信息。这包括关于运行进程的平台的信息:物理内存、CPU 数量和类型、库、命令行、线程堆栈和寄存器。它还可以提供关于 Java 运行时和 Java 应用程序的状态的信息,包括类装载器、线程、监视器、堆、对象、Java 线程、方法、编译的代码和字段及其值。
因为提供的数据范围非常广泛,DTFJ API 为创建各种工具提供了很大的灵活性。例如,在比较简单的层面上,它使工具能够查明各个缓存的大小和内容,从而更有效地调整这些缓存所需要的 Java 堆内存量。
开始使用 DTFJ
创建基于 DTFJ 的工具的第一步是获得与系统转储相关的 Image 对象,然后从 ImageAddressSpace 获得 ImageProcess 对象,见清单 2:
清单 2. 使用 DTFJ 获得当前进程
|
在大多数平台上,映像中只有一个 ImageAddressSpace 和 ImageProcess 对象;但是,大型机操作系统可能有多个实例。
获得 ImageProcess 对象之后,就可以访问本机线程,见清单 3:
清单 3. 获得线程和堆栈帧
|
还可以访问各个 ImageModule(库)对象,见清单 4:
清单 4. 获得已经装载的库
|
可以从 ImageProcess 对象获得 JavaRuntime,见清单 5:
清单 5. 获得 Java 运行时
|
这样就可以访问所有 Java 结构。
获得了 JavaRuntime 对象之后,就可以编写工具来探察正在运行的任何 Java 应用程序。清单 6 中的简单示例演示了如何遍历 Java 堆上的所有对象并统计每种类型的对象的数量:
清单 6. 统计转储中每种对象的数量
|
|
结束语
本文讨论的所有功能都可以帮助您诊断和解决在 Java 部署中遇到的开发和生产问题。结合使用这三种主要的设施来生成历史跟踪数据和详细的状态数据,再用简单的 API 访问状态数据,就可以以强大且灵活的方式探察 Java 应用程序并解决问题。
本文结束了对 Java 虚拟机的 IBM 实现中主要改进和改变的讨论。具体地说,我们讨论了内存管理、类共享和应用程序监视,描述了如何利用这些功能改进 Java 应用程序的性能和可用性。关于这些改进和其他改进的更多信息可以在 IBM Diagnostics Guide 中找到,还可以通过 IBM Runtimes and SDKs 论坛进行反馈和讨论(见 参考资料 中的链接)。
在这个系列的最后一篇文章中,Java 安全开发团队将讨论 IBM 对 Java 平台的安全改进。那篇文章将介绍每个安全组件以及它们提供的功能。
- 评论列表(网友评论仅供网友表达个人看法,并不表明本站同意其观点或证实其描述)
-

