




NoSQL 数据建模技术
全文译自墙外文章“NoSQL Data Modeling Techniques”,译得不好,还请见谅。这篇文章看完之后,你可能会对NoSQL的数据结构会有些感觉。我的感觉是,关系型数据库想把一致性,完整性,索引,CRUD都干好,NoSQL只干某一种事,但是牺牲了很多别的东西。总体来说,我觉得NoSQL更适合做Cache。下面是正文——
NoSQL 数据库经常被用作很多非功能性的地方,如,扩展性,性能和一致性的地方。这些NoSQL的特性在理论和实践中都正在被大众广泛地研究着,研究的热点正是那些和性能分布式相关的非功能性的东西,我们都知道 CAP 理论被很好地应用于了 NoSQL 系统中(陈皓注:CAP即,一致性(Consistency), 可用性(Availability), 分区容忍性(Partition tolerance),在分布式系统中,这三个要素最多只能同时实现两个,而NoSQL一般放弃的是一致性)。但在另一方面,NoSQL的数据建模技术却因为缺乏像关系型数据库那样的基础理论没有被世人很好地研究。这篇文章从数据建模方面对NoSQL家族进行了比较,并讨论几个常见的数据建模技术。
要开始讨论数据建模技术,我们不得不或多或少地先系统地看一下NoSQL数据模型的成长的趋势,以此我们可以了解一些他们内在的联系。下图是NoSQL家族的进化图,我们可以看到这样的进化:Key-Value时代,BigTable时代,Document时代,全文搜索时代,和Graph数据库时代:(陈皓注:注意图中SQL说的那句话,NoSQL再这样发展下去就是SQL了,哈哈。)
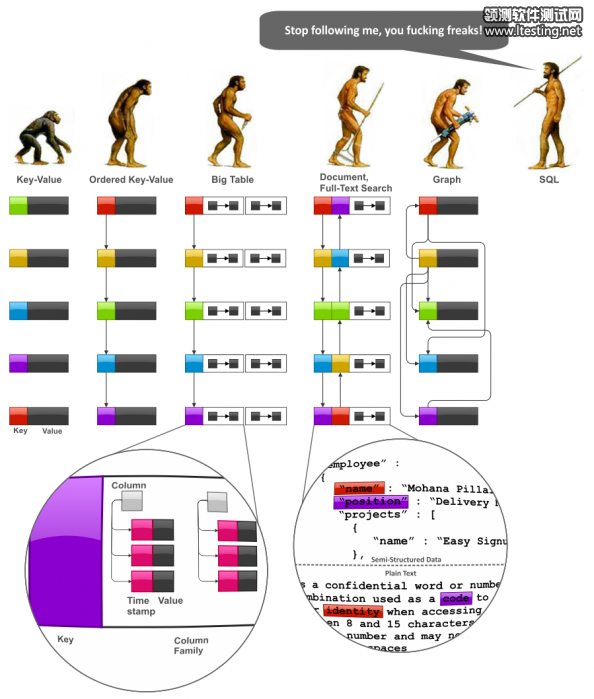
NoSQL Data Models
首先,我们需要注意的是SQL和关系型数据模型已存在了很长的时间,这种面向用户的自然性意味着:
最终用户一般更感兴趣于数据的聚合显示,而不是分离的数据,这主要通过SQL来完成。
我们无法通过人手工控制数据的并发性,完整性,一致性,或是数据类型校验这些东西的。这就是为什么SQL需要在事务,二维表结构(schema)和外表联合上做很多事。
另一方面,SQL可以让软件应用程序在很多情况下不需要关心数据库的数据聚合,和数据完整性和有效性进行控制。而如果我们去除了数据一致性,完整性这些东西,会对性能和分布存储有着重的帮助。正因为如此,我们才有数据模型的进化:
Key-Value 键值对存储是非常简单而强大的。下面的很多技术基本上都是基于这个技术开始发展的。但是,Key-Value有一个非常致命的问题,那就是如果我们需要查找一段范围内的key。(陈皓注:学过hash-table数据结构的人都应该知道,hash-table是非序列容器,其并不像数组,链接,队列这些有序容器,我们可以控制数据存储的顺序)。于是,有序键值 (Ordered Key-Value) 数据模型被设计出来解决这一限制,来从根本上提高数据集的问题。
Ordered Key-Value 有序键值模型也非常强大,但是,其也没有对Value提供某种数据模型。通常来说,Value的模型可以由应用负责解析和存取。这种很不方便,于是出现了 BigTable类型的数据库,这个数据模型其实就是map里有map,map里再套map,一层一层套下去,也就是层层嵌套的key-value(value里又是一个key-value),这种数据库的Value主要通过“列族”(column families),列,和时间戳来控制版本。(陈皓注:关于时间戳来对数据的版本控制主要是解决数据存储并发问题,也就是所谓的乐观锁,详见《多版本并发控制(MVCC)在分布式系统中的应用》)
Document databases 文档数据库 改进了 BigTable 模型,并提供了两个有意义的改善。第一个是允许Value中有主观的模式(scheme),而不是map套map。第二个是索引。 Full Text Search Engines 全文搜索引擎可以被看作是文档数据库的一个变种,他们可以提供灵活的可变的数据模式(scheme)以及自动索引。他们之间的不同点主要是,文档数据库用字段名做索引,而全文搜索引擎用字段值做索引。
Graph data models 图式数据库 可以被认为是这个进化过程中从 Ordered Key-Value 数据库发展过来的一个分支。图式数据库允许构建议图结构的数据模型。它和文档数据库有关系的原因是,它的很多实现允许value可以是一个map或是一个document。
NoSQL 数据模型摘要
本文剩下的章节将向你介绍数据建模的技术实现和相关模式。但是,在介绍这些技术之前,先来一段序言:
NoSQL 数据模型设计一般从业务应用的具体数据查询入手,而不是数据间的关系:
关系型的数据模型基本上是分析数据间的结构和关系。其设计理念是: ”What answers do I have?”
NoSQL 数据模型基本上是从应用对数据的存取方式入手,如:我需要支持某种数据查询。其设计理念是 ”What questions do I have?”
NoSQL 数据模型设计比关系型数据库需要对数据结构和算法的更深的了解。在这篇文章中我会和大家说那些尽人皆知的数据结构,这些数据结构并不只是被NoSQL使用,但是对于NoSQL的数据模型却非常有帮助。
数据冗余和反规格化是一等公民。
关系型数据库对于处理层级数据和图式数据非常的不方便。NoSQL用来解决图式数据明显是一个非常好的解决方案,几乎所有的NoSQL数据库可以很强地解决此类问题。这就是为什么这篇文章专门拿出一章来说明层级数据模型。
下面是NoSQL的分类表,也是我用来写这篇文章时做实践的产品:
Key-Value 存储: Oracle Coherence, Redis, Kyoto Cabinet
类BigTable存储: Apache HBase, Apache Cassandra
文档数据库: MongoDB, CouchDB
全文索引: Apache Lucene, Apache Solr
图数据库: neo4j, FlockDB
概念技术 Conceptual Techniques
这一节主要介绍NoSQL数据模型的基本原则。
(1) 反规格化 Denormalization
反规格化 Denormalization 可以被认为是把相同的数据拷贝到不同的文档或是表中,这样就可以简化和优化查询,或是正好适合用户的某中特别的数据模型。这篇文章中所说的绝大多数技术都或多或少地导向了这一技术。
