




网络分区带给分布式数据库的难题如何解决?
在OpenStack中,数据库是主要系统“状态”的主要来源。大部分Core Projects都使用传统关系型数据库作为系统数据和状态的存储,另外如Ceilometer使用了MongoDB,还有其他Incubator Projects使用了Redis作为队列或者状态存储。数据库给OpenStack提供了状态组件并把状态的“共享”问题交给了数据库,因此解决 OpenStack的扩展问题实际上就是解决使用的数据库本身的扩展问题。比如OpenStack HA Solution最令人头疼的就是传统关系数据库或者其他数据存储的扩展问题,数据库扩展问题的根源是其本身不支持分布式和良好的扩展性,而这个根源又会衍生出分布式系统最大的噩梦–“网络分区”。
下面会分析”网络分区“给数据库扩展带来的问题,同时在OpenStack组件中如何规避和解决。
一致性
现代软件系统由一系列“组件”通过异步、不可靠的网络相互沟通构建。理解一个可信赖的分布式系统需要对网络本身的分析,而“状态”共享就是一个最重要的问题。
举一个例子,当你发表一篇博文后,你可能想知道在你点击“发布”操作之后:
1. 从现在开始会对所有人可见;
2. 从现在开始会对你的连接可见,其他人会延迟;
3. 你也可能暂时不可见,但是未来会可见;
4. 现在可见或者不可见:发生错误
5. …… etc
不同的分布式系统会有对一致性和持久性相互影响的权衡和决定,比如Dynamo类系统通过NRW来指定一致性,如果N=3, W=2,R=1,你将会得到:
1. 可能不会马上看到更新
2. 更新数据会在一个节点失败后存活
如果你像Zookeeper来写入,那会得到一个强一致性保证:写操作会对所有人可见,比如这个写操作在一半以下的节点失败后仍然能够保证。如果你像MySQL写入,取决于你的事物一致性级别,你的写操作一致性会对所有人、你可见或者最终一致性。
网络分区
分布式通常假设网络是异步的,意味着网络可能会导致任意的重复、丢失、延迟或者乱序的节点间消息传递。在实际中,TCP状态机会保证节点间消息传递的不丢失、不重复、时序。但是,在Socket级别上,节点接发消息会阻塞,超时等等。
检测到网络失败是困难,因为我们唯一能跟得到其他节点状态的信息就是通过网络来得到,延迟跟网络失败也无从区分。这里就会产生一个基本的网络分区问题:高延迟可以考虑作为失败。当分区产生后,我们没有渠道去了解到其他节点到底发生了什么事: 它们是否还存活?或者已经crash?是否有收到消息?是否正在尝试回应。当网络最终恢复后,我们需要重新建立连接然后尝试解决在不一致状态时的不一致。
很多系统在解决分区时会进入一个特殊的降级操作模式。CAP理论也告诉我们妖么得到一致性要么高可用性,但是很少有数据库系统能够达到CAP理论的极限,多数只是丢失数据。
接下来的内容会介绍一些分布式系统是如何在网络失败后进行相关行为。
传统数据库与2PC
传统的SQL数据库如MySQL、Postgresql都提供一系列不同的一致性级别,然后通常都只能向一个primary写入,我们可以把这些数据库认为是CP系统(CAP理论),如果分区发生,整个系统会不可用(因为ACID)。
那么传统数据库是不是真的是强一致性?它们都是使用2PC策略来提交请求:
1. 客户端commit
2. 服务器端写操作然后回应
3. 客户端收到回应完成提交
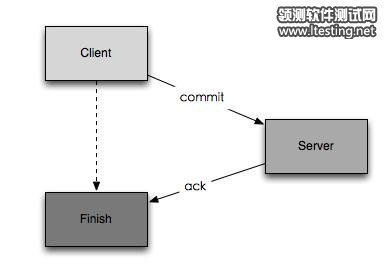
在这三个步骤中,可能发生不一致的情况在于2与3之间,当服务器写操作完成但是回应没有被客户端收到,无论是超时或者网络故障,客户端这时会认为这次操作没有完成,而事实上数据库已经写入。这时就会产生不一致的行为。也就是客户端得到的错误并不能解释到底服务器端有没有写入。
2PC不仅在传统SQL数据库被广泛使用,也有大量用户实现2PC在MongoDB之上来完成多键值事务操作。
那么如何解决这个问题?首先必须接受这个问题,因为网络失败地概率比较低,并且正好在服务器写操作完成与客户端得到回应之间失败。这使得受到影响的操作非常稀有,在大部分业务中,这个失败是可接受到。相对的,如果你必须要强一致性的实施,那么应该在业务中付诸行动,比如所有的事务写操作都是幂等的,是可重入的。这样当遇到网络问题时,retry即可而不管到底写操作有没有完成。最后,一些数据库可以得到事务ID,通过track事务ID你可以在网络故障后重新评估事务是否完成,通过数据库在网络恢复后检查其记录的事物ID然后回滚相应事务。
我们在OpenStack的选择就很有限,目前各个项目中并不是所有写操作都是幂等的,不过幸运的是,OpenStack的数据在罕见的2PC协议特例中损失是能接受的。
Redis
Redis通常被视为一个共享的heap,因为它容易理解的一致性模型,很多用户把Redis作为消息队列、锁服务或者主要数据库。Redis在一个server上运行实例视为CP系统(CAP理论),因此一致性是它的主要目的。
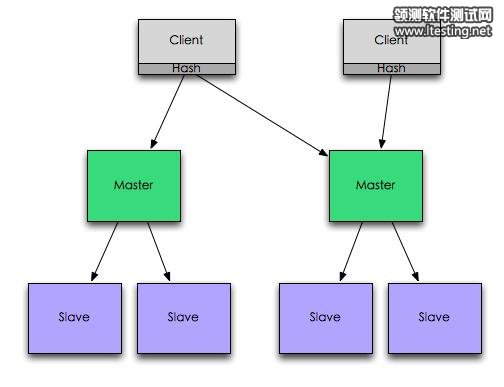
Redis集群通常是主备,primary node负责写入和读取,而slave node只是用来备份。当primary node失败时,slave node有机会被提升为primary node。但是因为primary node和slave node之间是异步传输,因此slave node被提升为primary node后会导致0~N秒的数据丢失。此时Redis的一致性已经被打破,Redis这个模式的集群不是一个CP系统!
Redis有一个官方组件叫Sentinel(参考Redis Sentinel,它是通过类似Quorum的方式来连接Sentinel instance,然后检测Redis集群的状态,对故障的primary节点试用slave节点替换。Redis官方号称这个是HA solution,通过Redis Sentinel来构建一个CP系统。
原文转自:http://os.51cto.com/art/201307/403298.htm
