




软件测试数据库中NoSQL漫谈
软件测试数据库中NoSQL漫谈
NoSQL,意即反SQL运动,是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于目前铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
什么是NoSQL?wiki上的定义是“NoSQL is a movement promoting a loosely defined class of non-relational data stores that break with a long history of relational databases”。其实并不存在一个叫NoSQL的产品,它是一类non-relational data stores的集合。NoSQL的重点是non-relational,而传统的数据库是relational。
我们都知道,传统关系型数据库的最大缺陷是扩展性,虽然各个数据库厂家都有cluster的解决方案,但是不管是share storage还是share nothing的解决方案,扩展性都十分有限。目前解决数据库扩展性的思路主要有两个:第一是数据分片(sharding)或者功能分区,虽然说可以很好的解决数据库扩展性的问题,但是在实际使用过程中,一旦采用数据分片或者功能分区,必然会导致牺牲“关系型”数据库的最大优势-join,对业务局限性非常大,而数据库也退化成为一个简单的存储系统。另外一个思路是通过maser-slave复制的方式,通过读写分离技术在某种程度上解决扩展性的问题,但这种方案中,由于每个数据库节点必须保存所有的数据,这样每个存储的IO subsystem必然成为扩展的瓶颈,而且masert节点也是一个瓶颈。总的来说,传统关系型数据库的扩展能力十分有限。
在说NoSQL之前,首先得说两个重要的概念,一个是CAP理论,另一个是BASE模型。
CAP
Consistency(一致性),数据一致更新,所有数据变动都是同步的
Availability(可用性),好的响应性能
Partition tolerance(分区容错性) 可靠性
CAP原理告诉我们,这三个因素最多只能满足两个,不可能三者兼顾。对于分布式系统来说,分区容错是基本要求,所以必然要放弃一致性。对于大型网站来说,分区容错和可用性的要求更高,所以一般都会选择适当放弃一致性。对应CAP理论,NoSQL追求的是AP,而传统数据库追求的是CA,这也可以解释为什么传统数据库的扩展能力有限的原因。
BASE
Basically Availble:基本可用
Soft-state: 软状态/柔性事务
Eventual Consistency:最终一致性
BASE模型是传统ACID模型的反面,不同与ACID,BASE强调牺牲高一致性,从而获得可用性。基本可用是指通过sharding,允许部分分区失败。软状态是指异步,允许数据在一段时间内的不一致,只要保证最终一致就可以了。最终一致性是整个NoSQL中的一个核心理念,很多NoSQL产品就是基于最终一致性而设计的,包括Amazon的Dynamo.
NoSQL产品简介
NoSQL是很多non-relational data stores的集合,总体来说,他们基本都是基于Key-value形式的一种分布式存储,但是每一种NoSQL产品都面向一个特定的应用场景,根据这些应用场景,我们可以把NoSQL分为以下类型(参考了wiki上的定义,只列举了我们比较熟悉的产品):
KV cache:Memcached
KV store:Tokyo Tyrand/Cab.net,Memcachedb,Berkley DB
Eventually consistent KV store:dynamo,voldemort,Cassandra
Wide columnar store:BigTable,Cassandra,Hbase
document store:MongoDB
KV Cache类型不具有持久化存储的功能,其中的memcached被我们广泛使用,用来缓解数据库的压力,至于数据持久化存储的功能则由数据库来替代了。
KV store具备了持久化存储的功能,其中的memcachedb是新浪在memcached的基础上,采用Berkley DB作为存储层开发的分布式KV store。Tokyo Tyrand/Cabinet是日本最大的SNS社交网站mixi.jp开发的KV store,其中TC是一个NoSQL的数据库,用来做持久化数据存储,TT则是TC的网络接口(兼容memcached协议)。至于Berkley DB则是一个嵌入式数据库,现在掌握在Oracle手中。
Eventually consistent KV store是以最终一致性原理设计的一类KV store,包括Amazon的Dynamo,Lindedin的voldemort以及Facebook的Cassandra,Dynamo的主要特点是:分布式(去中心化),高可用,可扩展,永远可写等等。Dynamo的设计思想是分布式系统中最重要的理论之一,另外一个是Bigtable。
Wide columnar store包括Bigtable,Cassandra和Hbase,这种类型是用来处理结构化数据的,它有几个特点:具备大规模扩展能力,有类似数据库中column的概念,非常灵活的schema,采用memtable/sstable的存储机制,并基于列存储。Cassandra采用了Dynamo最终一致性的理念,并借鉴了Bigtable的数据模型和实现方式,所以很多人把他看作是开源版本的Bigtable+Dynamo,这种类型的KV store是我们关注的重点。
document store是基于文档的KV store,这种类型主要面向海量数据处理,其中MongoDB的特点是支持非常复杂的数据类型,而且查询语言非常强大,有些类似于关系型数据库。但它并不适合大规模并发读写的应用。
下面介绍几个分布式系统的概念:consistent hashing,virtual node,quorum,vector clock:
consistent hashing
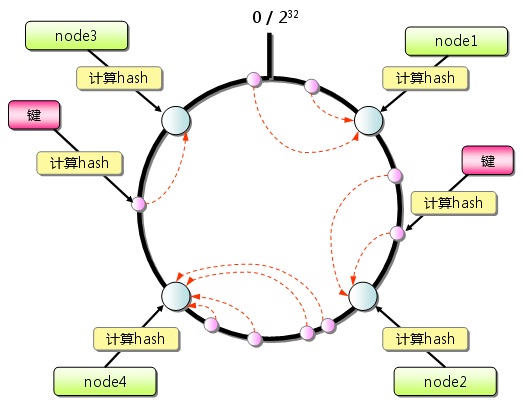
我们通常使用的hash算法是hash() mod n,但是如果发生某个节点失效时,无法快速切换到其他节点。为了解决单点故障的问题,我们为每个节点都增加一个备用节点,当某个节点失效时,就自动切换到备用节点上,类似于数据库的master和slave。但是依然无法解决增加或删除节点后,需要做hash重分布的问题,也就是无法动态增删节点。这时就引入了一致性hash的概念 ,将所有的节点分布到一个hash环上,每个请求都落在这个hash环上的某个位置,只需要按照顺时针方向找到的第一个节点,就是自己需要的服务节点。当某个节点发生故障时,只需要在环上找到下一个可用节点即可。一致性hash解决了增删节点后需要hash重分布的问题,是分布式系统的基础。
virtual node
虚拟节点是在一致性hash的基础上,把一台物理节点虚拟成多个虚拟节点,并映射到hash环的不同位置上。这样的好处是可以根据机器硬件的性能,灵活的定义虚拟节点的个数。这里所说的虚拟节点不是用虚拟机技术实现的,而是把一个物理节点映射为多个虚拟节点。
quorum NRW
N: 复制的节点数,即一份数据被保存的份数。
R: 成功读操作的最小节点数,即每次读取成功需要的份数。
W: 成功写操作的最小节点数 ,即每次写成功需要的份数。
这三个因素决定了可用性,一致性和分区容错性。对于一个分布式系统来说,N通常都大于3,也就说同一份数据需要保存在三个以上不同的节点上,以防止单点故障。W是成功写操作的最小节点数,这里的写成功可以理解为“同步”写,比如N=3,W=1,那么只要写成功一个节点就可以了,另外的两份数据是通过异步的方式复制的。R是成功读操作的最小节点数,读操作为什么要读多份数据呢?在分布式系统中,数据在不同的节点上可能存在着不一致的情况,我们可以选择读取多个节点上的不同版本,来达到增强一致性的目的。下面我们分析几个典型的场景:
N=W,R=1,这种情况是最强一致性的,每个节点都被同步写入,读取任意节点即可,所以读取的性能最高,但是可用性是最差的,因为必须保证每个节点都必须成功写人。
R+W>N,这种情况也是可以保证一致性的,因为读取数据的节点和同步写入的节点至少有一个重叠,比如N=3,W=2,R=2,每份数据有三个复本,每次同步写成功两份数据,每次读取至少两份数据,则说明读取的数据至少有一份是同步写人的最新数据,所以一致性可以得到保证,N=3,W=2,R=2是可用性和性能的一个平衡。
N=R,W=1,这种情况最大程度保证了写的性能,数据只写一份即成功,而读取时则需要所有的数据复本,以此来达到保证一致性的目的,但是同样牺牲了可用性。
W+R<=N,这种情况是不保证一致性的,因为读取和写入的节点可能存在不重叠的情况,在数据同步到其他节点的这段时间窗口内,可能会出现数据不一致的情况。
