




oracle 索引(3)
4、如果一个表很大,建立索引的时间很长,因为建立索引也会产生大量的redo信息,所以在创建索引时可以设置不产生或少产生redo信息。只要表数据存在,索引失败了大不了再建,所以可以不需要产生redo信息。
5、建索引的时候应该根据具体的业务SQL来创建,特别是where条件,还有where条件的顺序,尽量将过滤大范围的放在后面,因为SQL执行是从后往前的。(小李飛菜刀)
索引常见操作
改变索引:
SQL> alter index employees_last _name_idx storage(next 400K maxextents 100);
索引创建后,感觉不合理,也可以对其参数进行修改。详情查看相关文档
调整索引的空间:
新增加空间
SQL> alter index orders_region_id_idx allocate extent (size 200K datafile '/disk6/index01.dbf');
释放空间
SQL> alter index oraers_id_idx deallocate unused;
索引在使用的过程中可能会出现空间不足或空间浪费的情况,这个时候需要新增或释放空间。上面两条命令完成新增与释放操作。关于空间的新增oracle可以自动帮助,如果了解数据库的情况下手动增加可以提高性能。
重新创建索引:
所引是由oracle自动完成,当我们对数据库频繁的操作时,索引也会跟着进行修改,当我们在数据库中删除一条记录时,对应的索引中并没有把相应的索引只是做一个删除标记,但它依然占据着空间。除非一个块中所有的标记全被删除的时,整个块的空间才会被释放。这样时间久了,索引的性能就会下降。这个时候可以重新建立一个干净的索引来提高效率。
SQL> alter index orders_region_id_idx rebuild tablespace index02;
通过上面的命令就可以重现建立一个索引,oracle重建立索引的过程:
1、锁表,锁表之后其他人就不能对表做任何操作。
2、创建新的(干净的)临时索引。
3、把老的索引删除掉
4、把新的索引重新命名为老索引的名字
5、对表进行解锁。
移动所引:
其实,我们移动索引到其它表空间也同样使用上面的命令,在指定表空间时指定不同的表空间。新的索引创建在别位置,把老的干掉,就相当于移动了。
SQL> alter index orders_region_id_idx rebuild tablespace index03;
在线重新创建索引:
上面介绍,在创建索引的时候,表是被锁定,不能被使用。对于一个大表,重新创建索引所需要的时间较长,为了满足用户对表操作的需求,就产生的这种在线重新创建索引。
SQL> alter index orders_id_idx rebuild online;
创建过程:
1、锁住表
2、创建立临时的和空的索引和IOT表用来存在on-going DML。普通表存放的键值,IOT所引表直接存放的表中数据;on-gong DML也就是用户所做的一些增删改的操作。
3、对表进行解锁
4、从老的索引创建一个新的索引。
5、IOT表里存放的是on-going DML信息,IOT表的内容与新创建的索引合并。
6、锁住表
7、再次将IOT表的内容更新到新索引中,把老的索引干掉。
8、把新的索引重新命名为老索引的名字
9、对表进行解锁
整合索引碎片:
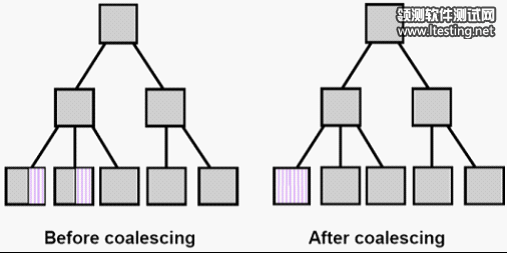
如上图,在很多索引中有剩余的空间,可以通过一个命令把剩余空间整合到一起。
SQL> alter index orders_id_idx coalesce;
删除索引:
SQL> drop index hr.departments_name_idx;
分析索引
检查所引的有效果,前面介绍,索引用的时间久了会产生大量的碎片、垃圾信息与浪费的剩余空间了。可以通过重新创建索引来提高所引的性能。
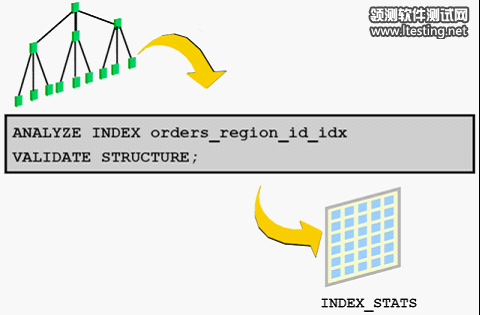
可以通过一条命令来完成分析索引,分析的结果会存放在在index_stats表中。
查看存放分析数据的表:
SQL> select count(*) from index_stats;
COUNT(*)
----------
0
执行分析索引命令:
SQL> analyze index my_bit_idx validate structure;
Index analyzed.
再次查看 index_stats 已经有了一条数据
SQL> select count(*) from index_stats;
COUNT(*)
----------
1
把数据查询出来:
SQL> select height,name,lf_rows,lf_blks,del_lf_rows from index_stats;
HEIGHT NAME LF_ROWS LF_BLKS DEL_LF_ROWS
---------- ---------------------------------------------------------------------- ---------- -----------
2 MY_BIT_IDX 1000 3 100
分析数据分析:
(HEIGHT)这个所引高度是2 ,(NAME)索引名为MY_BIT_IDX ,(LF_ROWS)所引表有1000行数据,(LF_BLKS)占用3个块,(DEL_LF_ROWS)删除100条记录。
这里也验证了前面所说的一个问题,删除的100条数据只是标记为删除,因为总的数据条数依然为1000条,占用3个块,那么每个块大于333条记录,只有删除的数据大于333条记录,这时一个块被清空,总的数据条数才会减少。
原文转自:http://www.cnblogs.com/fnng/archive/2012/10/10/2719221.html
