需求版本化
|
背景
方法1:包括一切
一个新的需求属性
例子
方法2:利用一个变更请求管理器
例子
表2:使用变更请求管理器的例子
一个现实的场景:这种情况在你的身边发生过吗?
结论
本文来自于 Rational Edge:作者提出了两种用于跨多个产品发布版本场合管理需求的多个版本的方法。第一种方法使用了IBM
Rational RequisitePro 或者其它需求管理工具。第二种方法使用了变更管理工具,例如,IBM Rational
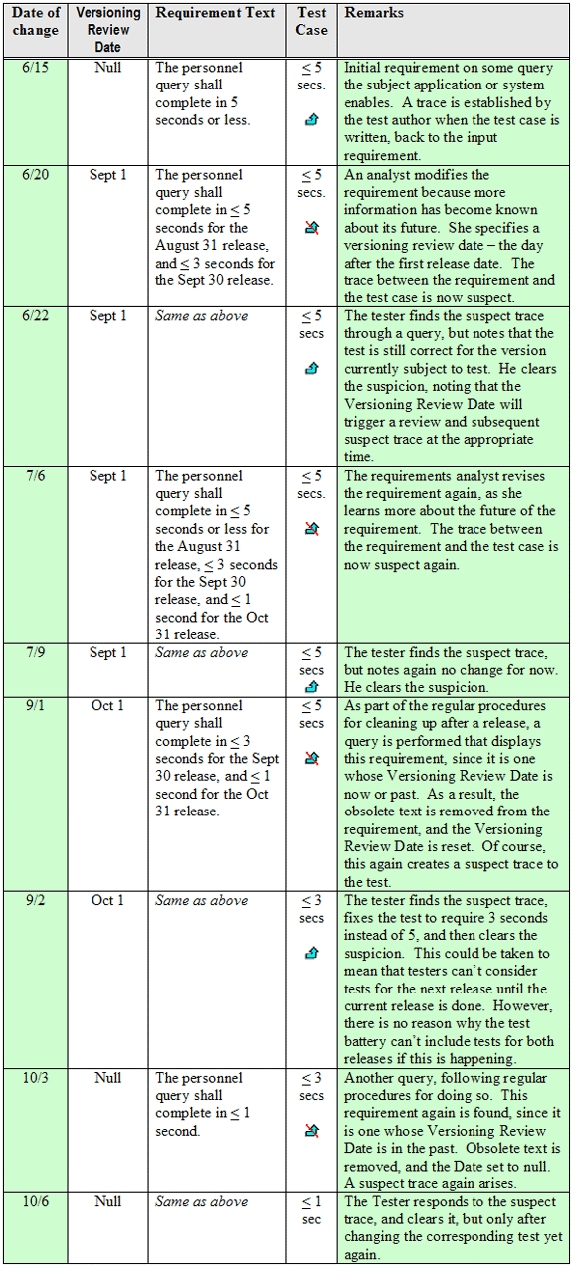
ClearQuest,它可以与需求管理工具结合使用。 这就产成了一个有趣的管理问题。在一个大的系统中,可能有许多需求,数量多得使我们很难在适当的时候记得去变更需求。理想情况下,当一个分支被合并时,需求就被正确地更新了。对受此需求影响的测试的跟踪应当被认为是可疑的,这样测试人员会自动地得到通知,测试用例可能也需要进行变更。 在本文中,我提出了两种处理此问题的方法。 人们可能认为实现文件版本化的软件配置管理(SCM)工具,比如 IBM Rational ClearCase,会满足这种需求。不幸地是,像这样的版本控制能力不适用于这种要求,除非我们严格地将一个需求放在一个文件中,并且为每一个需求都维护一个单独的文件 —— 这其实是十分不实际的!许多需求管理工具为每一个需求都保持了历史记录,但是并不能实现版本化。由这些工具提供的关于需求的完整视图仅仅是“Main/Latest”。 以前我们已经尝试了好几种方法来处理需求版本化,包括复制需求库和将需求文档复制到包含需求文本(其缺少属性和跟踪信息)的临时文档中。这些方法都不令人满意。要么是劳动密集型的并且容易出错,要么削弱了成功管理需求所需要的需求工具特性,而这些特性是为了应对市场影响或者其它因素而做出改变所需要的。 让我们考虑一下跨多个产品发布版本来维护对需求变化的可追溯性的两种方法。第一种技术利用了 IBM Rational RequisitePro,第二种则同时使用了 RequisitePro 和 IBM Rational ClearQuest。这两种方法都通过一种简单的原则来描写这些需求,只包括产品的基本特性。虽然我们使用了IBM Rational产品,但这些方法也应该可以扩展到其它拥有类似能力的产品中。 第一种方法依赖于一个简单的原则,它扩展了如何定义需求的传统规则。目前,普遍应用于需求定义的规则很少。唯一保持一致的规则是通常被称作为 Zen Rule 的规则:一个需求必须是对所需要的某件事物的陈述。为了改进这个方法,我们需要扩展我们需求的范围:一个需求必须总是描述那些在任何时间点上被需要的事情,不管是现在还是可预知的将来(只要在我们知道的范围之内)。除了使我们的方法更容易之外,这个新的范围也是有价值的,因为这样的需求变成了在整个过程中我们需要了解的所有基本需求的详细叙述。这对系统的构架和设计的帮助都是很有意义的。 例如,我们假设一个系统的需求是在下一个发布版本中需要四个窗口部件,而再下一个发布版本需要6个窗口部件。然后,我们的方法表明这个需求应该这样描述一个完整的需要:SUPP42: XYZ 应用程序将在2006年6月30日的发布版本中包含四个窗口部件,而接下来的发布版本中将有六个窗口部件。 注意,这并不意味着我们在更新需求时一定要包含过去的信息。从需求分析的角度来看,如果2006年7月1日我们碰巧去变化了需求,读到以下的信息:SUPP42:XYZ应用程序将有6个窗口部件,这样是没什么问题的。如果我们这样做了,那么对于 SUPP42 来说,先前的需求版本应该被储存在 RequisitePro 的历史记录中,并且它也仍然是可以访问的。更重要的是,在下面所描述的机制将告诉我们一个变化已经发生了。 为了改进这种方法,我建议对每一个需求类型增加一个新的属性,这些需求可以被基于多版本的发行版本使用。可以将此属性称为版本评审日期(Versioning Review Date)。当一个需求分析师因为版本控制的目的要评审需求文本时间时候,我们会为每一个需求定义一个新的的Versioning Review Date 属性。当它是空白时,说明此需求当前没有必需被评审。任何在时间上其描述与多个状态相关的需求,都应当被需求分析师分配一个日期值。Versioning Review Date 应当与分析师期望需求的某些部分将会变化或者作废的时间一致。 下面这个例子阐述了“包含一切(all inclusive)”的方法是如何使用的。表1中的第一列中记录了每一行所显示的变化日期。Versioning Review Record 一列中表明了一个变更请求是否是打开的,如果是,那么它还包含着Version Review Date 记录属性的值。Requirement Text 一列显示了需求的当前文本。Test Case 列保存了补充需求的值,这些需求将通过测试用例来测试。 蓝色的箭头表示一个追踪,红色斜向下的箭头表示一个可疑追踪。由于有其它适当的成对的需求与测试用例,分析师之前并已经注意到(通过被叫作可追踪性)这个需求与这个测试用例是有联系的。这种关系很简单:如果其中的一个变化了,另一个也会变化,因此从分析师的角度来看应该关注这个问题。需求管理工具注意到需求已经变化了。因此这样就使追踪值得怀疑,表明这个测试用例值得注意。我们的方法当中的一部分就会对可疑追踪进行定期地询问。它们包括一个早期报警系统,以此来确保变化对需求的影响可以跨过产品版本被分析,并在需要的时候被处理。 最后,只需要使事情保持简单,让我们假定这个应用了样例需求的应用程序已经有了三次发布:8月31日,9月30日和10月31日。 表1:“包含一切”方法的例子
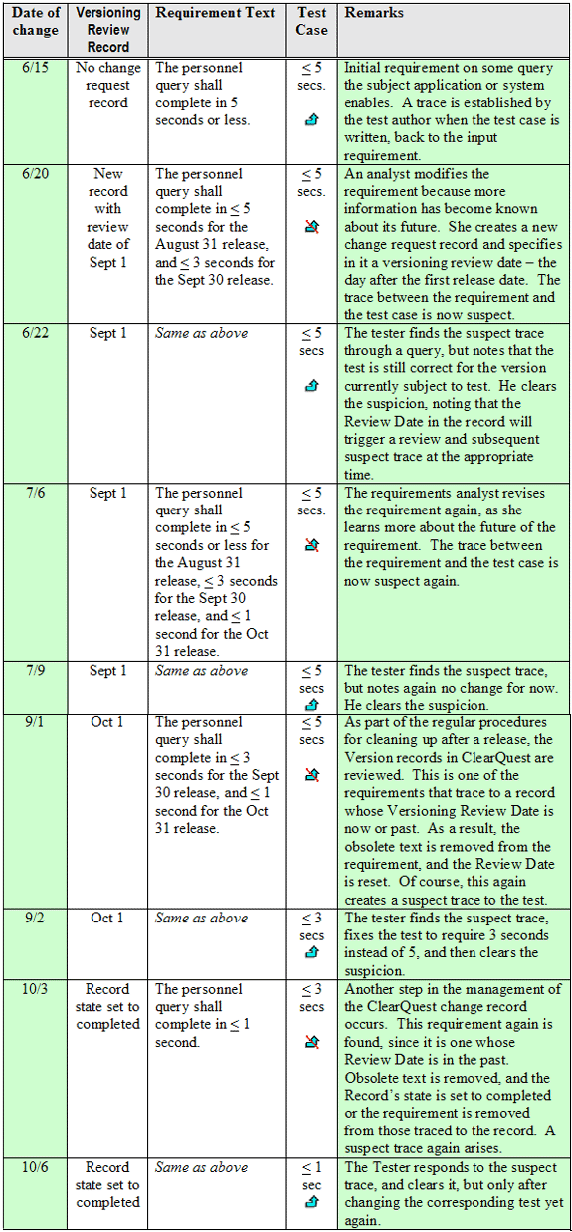
这个替代的方法是对以上描述的“包含一切”方法的变种。它利用了IBM Rational ClearQuest 的可用性,或者其它任何支持需求追溯性的变更请求管理器。这种方法有以下三个基本步骤: 我们书写需求,以便它们总是能够描述在任何时间上被需要的事情,正如“包含一切”的方法中的一样。 当然,这里的好处是不用有人必须记得要在需求管理工具中运行查询,来看什么需求应该接受一个版本控制的评审。变更管理工具现在却包含了这些信息。 表2显示的这个例子中,第一列中记录了每一行所显示的变化日期。Versioning Review Record 表示一个变更请求记录,其包含了对每个被追踪需求的评审日期。其余的列保存着与前一个例子中的表1相同的信息。值得注意的是通过这种方法使用变更请求可以简化后续的工作,因为一个记录可以表示变更了许多需求的需要。 此外,假定这个应用了此需求的应用程序已经有了三次发布:8月31日,9月30日和10月31日。
由于一个国防应用软件,Ephemeris Information Systems Inc(不是公司真正的名字)延迟了新的 Ephemeris Database 的开发周期,这个数据库是与跟踪地球轨道上许多人造卫星的信息相关的。跟踪太空垃圾与活动的卫星对在太空中的任何空间活动都是很重要的,并且无人航天器也是相当昂贵,如果它们与太空的其它物体相撞,将会导致一场灾难。数据的测试进行得很顺利。尤其是对于特殊属性(让我们暂且称之为 Cheese 吧)的查询进行得很快,测试表明对这个属性的查询情况是,稍微超过了任务设计说明书的指标。 一天,从事于这个程序的测试人员注意到,一个说明了 Cheese 属性可能值的需求最近已经变化了,不再是两个字节。上升到八个字节就应该存储这些可能值。关于是否有变更计划的必要还没有决定下来,因此他还不能构建并执行适当的测试,他找到他在开发工作室的朋友问他这个需求变化是否已经被注意到了。 这个开发人员看起来十分惊恐,她问是谁做了这个变更,并拿起电话问分析师:“我们先前怎么没有听到关于 Cheese 变化的事呢?”这个分析师回答说,“我们起初也不知道这个值会那么大,所以最初的需求仅仅只有两个字节。但在项目开发开始之后不久,我们才知道需要更大的值,但是我们知道原型是事先已经构造好了的,而且两个字节对于那个原型已经足够了,所以我们就把这个需求搁置一边。不幸的是,我们直到最近才记得做这个变更,我们只是忘了。” 这个开发人员说了谢谢就挂断电话。接下来的几天,他们作了各种尝试,但是没有人能够找到一个办法解决这个正在笼罩整个项目的问题。这个开发人员担心的最糟糕的事发生了。在两个字节的时候,这个数据库自动缓存了大量的 Cheese 值,其产生的查询性能是可接受的 —— 查询性能超过了需求所需要的35%。然而,在开发前期,他们已经意识到如果 Cheese 的值超过了四个字节,将会需要一个完全不同的数据库组织方式,一个不同的数据表结构(schema)来达成所需要的性能。“嗯,Cheese 值决不会超过四个字节”,有人这样说。事实上,大家已经知道在某些情况下,将会达到八个字节。项目开发采用更容易实现的数据表结构继续进行着,因此两个星期的时间内将会遇到更多困难,但是可能不需要两个星期,计划就会被解救。 现在,随着更复杂计划的需求渐渐明了,更长的开发时间将会花在为旧的 schema 构建数据转换上,幸运的是,在良好的子系统的设计中,查询管理是独立的,因此为新的 schema 重新设计查询的花费不会太高。然而最后,在某些事情变得更复杂的时候,新的 schema 是更好的数据架构的组成部分之一,使得后来处理程序中所发生的许多来自用户的无法预料的变更变得更加容易了。 总之,两个需求 —— 一个仅仅针对早期的迭代,一个对后来的产品系统是必要的 ― 应该事先都了解清楚。原型开发总会使成本略高一些,但是团队可以检验一个更复杂,但却更被需要的数据架构,这会很快在得到高性能查询中显示其价值。 需求版本化是一个过程,其记录了对特定需求随着时间进行多次变更的所预期的需要。对于大多数项目,实施需求版本化最好的原因是使团队能够准确地确定一个需求如何,以及为什么要从一个发布版本变更到下一个发布版本,因此测试用例也可以相应地被修改。需求版本化也简化了需求审计的功能,有助于确保产品满足需求,并因此改进质量。最后,它可以使构架人员和设计人员能够看到完整的最终系统范围,改进架构和系统设计的健壮性。 正如以上方法和相应的例子所阐述的一样,对于开发团队来说通过使用现有的工具来实现需求版本化是非常简单的,这只需要改变一下需求编写的方式,并添加一些新的流程。 
|