
【导读:别让AI测试沦为“数字游戏”】 AI一夜之间能吐出成千上万条测试用例,但面对领导的灵魂拷问——“这些用例到底比人工强在哪?”团队却往往哑口无言。 在本文中,领测老贺将经典软件工程方法论 ODC(正交缺陷分类法) 创造性复用到AI测试场景中。文章拒绝空谈概念,直接给出一套可量化的评估体系:不再单纯追逐用例数量,而是通过 Defect Type(缺陷类型)、Impact(影响程度) 和 Trigger(触发条件) 来精准“称重”AI的发现能力。 无论你是想证明AI测试的业务价值,还是想科学指导Prompt…

📖导读 摘要:小张兴奋地把屏幕转向我时,我正被一个跨域cookie的问题折磨得焦头烂额。"贺老师你看!"他眼睛发亮,"通义千问10分钟生成200条测试用例,覆盖大部分正向流程!"屏幕上密密麻麻的测试步骤像蝗虫过境般排列整齐。我瞥了一眼最顶端的用例标题——"用户正常登录流程",底下是教科书般的步骤描述。那一刻,我看着他... 核心观点:当下企业热衷 AI 测试工具带来的高效率(如快速生成海量测试用例),却普遍忽视其存在的深层问题 ——AI 仅擅长模式复制,无法识别未知风险和边缘场景,且易因 “高覆盖率” 数据掩盖质量…
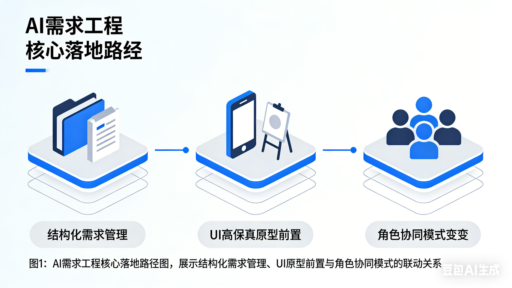
随着AI大模型技术的成熟,软件工程领域正经历从流程到工具、从角色到方法论的全方位变革。领测老贺整合“AI重塑软件工程”系列公众号文章核心内容,沿着“需求工程变革→逆向建模突破→实践工具落地→方法论优化”的逻辑脉络,系统拆解AI驱动软件工程的关键环节,分析其对传统体系的冲击,并展望未来发展方向。 一、AI驱动的软件工程核心变革环节 (一)需求工程与开发流程的重构:结构化规范先行 传统软件工程遵循“需求→设计→开发→测试→部署”的线性或迭代流程,而AI技术的介入首先推动了需求工程的结构化转型,并重塑了全流程的协作模式。…

原文:Daniel Knott 翻译:领测老贺 随着人工智能系统愈发先进并融入到了实际应用中,为确保其质量、可靠性与性能,将变得前所未有的重要。在本文中,我想分享关于 “测试左移” 如何改进通过人工智能进行开发的思考 —— 特别是通过对人工智能的提示词进行测试。 无论你是在处理大型语言模型(LLMs)、开发 AI 驱动的应用程序,还是为生成式工具设计提示词,在开发生命周期的早期阶段开展测试都是一项高效策略,并且能取得显著的收益。 什么是测试左移? 测试左移(Shift Left Testing)是一种软件开发实践,…
